HBase 学习:基础知识
本文最后更新于:2021年6月10日 下午
本文主要介绍 HBase 的设计目标、相关生态、数据模型和系统架构。
简介
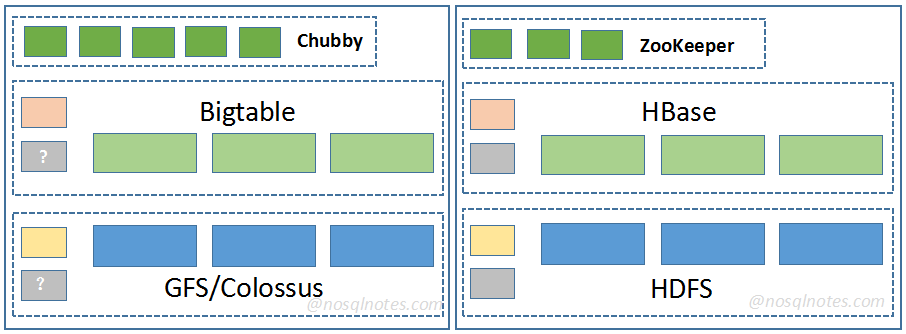
HBase 是高可靠性、高性能、面向列、可伸缩、可实时读写的分布式数据库,最初是 Google Bigtable 论文的开源实现。
设计目标
Scalability:HBase 底层基于 HDFS,支持扩展,并且可以随时添加或者减少节点
High Performance:底层的 LSM-Tree 数据结构,使得 HBase 具备非常高的写入性能。RowKey 有序排列、主键索引和缓存机制使得 HBase 具备一定的随机读写性能。
High Availability:基于 zookeeper 的协调服务,能够保证服务的高可用行。HBase 使用 WAL 和 replication 机制,前者保证数据写入时不会因为集群异常而导致写入数据的丢失,后者保证集群出现严重问题时,数据不会发生丢失和损坏。
相关生态
对于 HBase 不适用的场景,可以借助于强大的生态圈,架设 Phoenix、Spark 或者其他第三方组件,就可以有效地扩展 HBase 的使用场景。
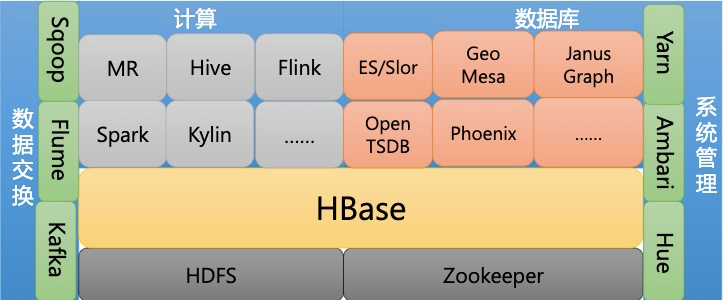
- Spark:基于内存计算的大数据计算引擎,提供海量数据的离线分析计算能力和实时流计算能力
- Phoenix:关系型数据库引擎,提供操作 HBase 的 SQL 接口,支持聚合运算,支持具有完整 ACID 语义的跨行及跨表事务,支持二级索引
- OpenTSDB:时序数据存储,提供基于 Metrics、时间和标签的一些组合维度查询与聚合能力
- GeoMesa:时空数据存储,提供基于时间和空间范围的索引能力
- JanusGraph:图数据存储,提供基于属性、关系的图索引能力
数据模型
术语
Table(表格)
- A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map.
- 一个表是一个包含海量 Key-Value 对的 Map,数据是持久化存储的。
- 这个大的 Map 需要支持多个分区来实现分布式。
- 这个 Map 按照 Key 进行排序,这个 Key 是一个由 {Row Key, Column Key, Timestamp} 组成的多维结构。
- 每一行列的组成并不是严格的结构,而是稀疏的,也就是说,行与行可以由不同的列组成
Row(行)
- 每一行数据都拥有一个唯一的 RowKey,可以将 Rowkey 理解为主键。
- RowKey 是一个 Byte String,通常长度在 10~100Bytes 左右,建议不超过 4KB,最大为 64KB。一行中包含一个或多个列。
- Bigtable 支持 Row 级别操作的原子性。
- 所有的数据按照 Row Key 的字典顺序进行排序。
- 数据的存储目标是相近的数据存储到一起。一个常用的行的 key 的格式是网站域名。如果你的行的 key 是域名,你应该将域名进行反转 (org.apache.www, org.apache.mail, org.apache.jira) 再存储。这样的话,所有 Apache 域名将会存储在一起,好过基于子域名的首字母分散在各处。
Column(列)
- HBase 中列的组成结构为 Family:Qualifier
Column Family(列族)
- 权限控制的最小单元。
- HBase 把同一列族里面的数据存储在同一目录下,由几个文件保存。
- 一个 Column Family 通常是一个或多个相同类型的列的集合,这样在数据压缩率上可以获取更好的效果。
- Column Families 的数量通常不建议过多,通常小于 5 个。
- 每一个列族拥有一系列的存储属性,例如值是否缓存在内存中,数据是否要压缩或者他的行 key 是否要加密等等
- 表格中的每一行拥有相同的列族,尽管一个给定的行可能没有存储任何数据在一个给定的列族中。
Column Qualifier(列的限定符)
- 列的限定符是列族中数据的索引。
- 例如给定了一个列族 content,那么限定符可能是 content:html,也可以是 content:pdf。
- HBase 表中的每个列都归属于某个列族,列族必须作为表模式 (schema) 定义的一部分预先给出。如 create ‘test’, ‘course’。
- 列名以列族作为前缀,每个“列族”都可以有多个列成员 (column)。如 course:math, course:english,新的列族成员(列)可以随后按需、动态加入。
- Cell(单元)
- 由行和列的坐标交叉决定。
- 单元格是有版本的。
- 单元格的内容是未解析的字节数组。
- 单元格是由行、列族、列限定符、值和代表值版本的时间戳组成的({row key, column( = +), version} )唯一确定单元格。
- cell 中的数据是没有类型的,全部是字节码形式存储。
- Timestamp(时间戳)
- 时间戳是写在值旁边的一个用于区分值的版本的数据。
- 默认情况下,时间戳表示的是当数据写入时 RegionSever 的时间点,但你也可以在写入数据时指定一个不同的时间戳。
- 在 HBase 每个 cell 存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
- 时间戳的类型是 64 位整型。时间戳可以由 HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
- Region(域)
- BigTable 中称为 Tablet
- HBase 自动把表水平划分成多个区域(Region),每个 Region 会保存一个表里面某段连续的数据。
- Region 是数据分布与负载均衡的基本单元。
- 每个表一开始只有一个 Region,一个 Region 增长到一定大小之后可以自动分裂成两个 Region。
- 多个 Region 可以合并成一个大的 Region。
视图
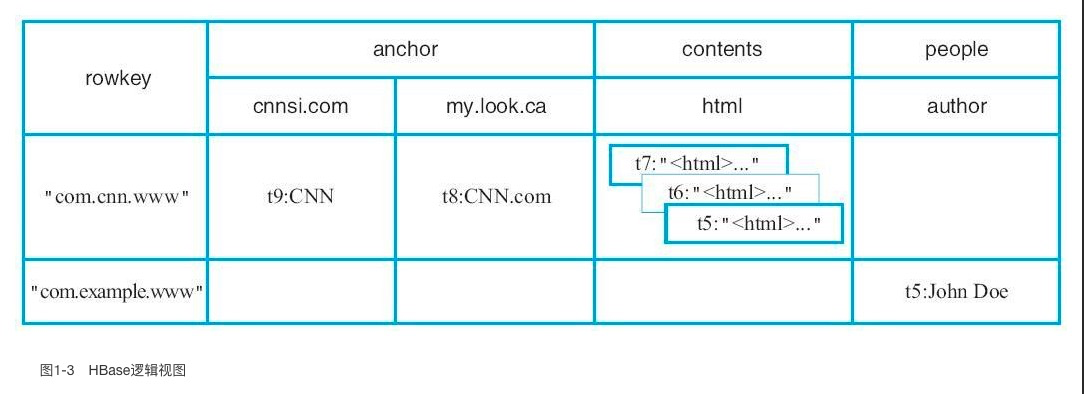
逻辑视图
一个名为 webable 的表格,表格中有两行(com.cnn.www 和 com.example.www)和三个列族(contents, anchor 和 people)。在这个例子当中,第一行(com.cnn.www)中 anchor 包含两列(anchor:cssnsi.com, anchor:my.look.ca)和 content 包含一列(contents:html)。这个例子中 com.cnn.www 拥有 5 个版本而 com.example.www 有一个版本。contents:html 列中包含给定网页的整个 HTML。anchor 限定符包含能够表示行的站点以及链接中文本。people 列族表示跟站点有关的人。
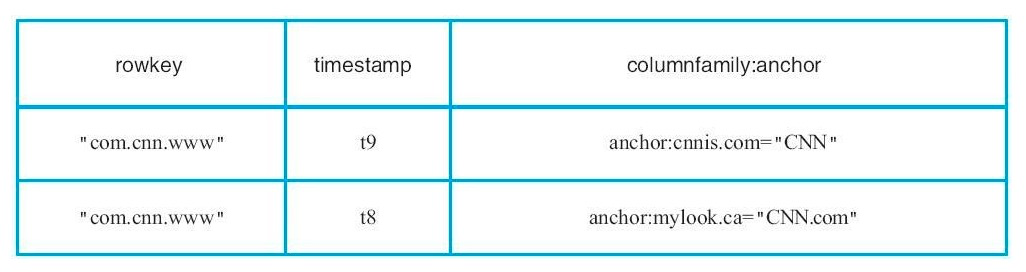
物理视图
尽管一个概念层次的表格可能看起来是由一些列稀疏的行组成,但他们是通过列族来存储的。一个新建的限定符 (column_family:column_qualifier)可以随时地添加到已存在的列族中。
列族 anchor 的所有数据存储在一起:
列族 contents 的所有数据存储在一起:
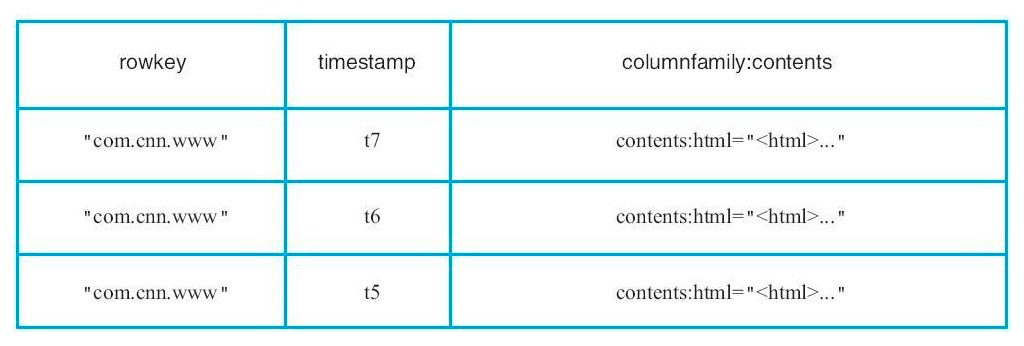
在 HBase 中,表格中的单元如果是空将不占用空间或者事实上不存在。因此对于返回时间戳为 t8 的 contents:html 的值的请求,结果为空。同样的,一个返回时间戳为 t9 的 anchor:my.look.ca 的值的请求,结果也为空。如果没有指定时间戳的话,会返回特定列的最新值。对有多个版本的列,优先返回最新的值,因为时间戳是按照递减顺序存储的。因此对于一个返回 com.cnn.www 里面所有的列的值并且没有指定时间戳的请求,返回的结果会是时间戳为 t6 的 contents:html 的值、时间戳 t9 的 anchor:cnnsi.com 的值和时间戳 t8 的 anchor:my.look.ca。
系统架构
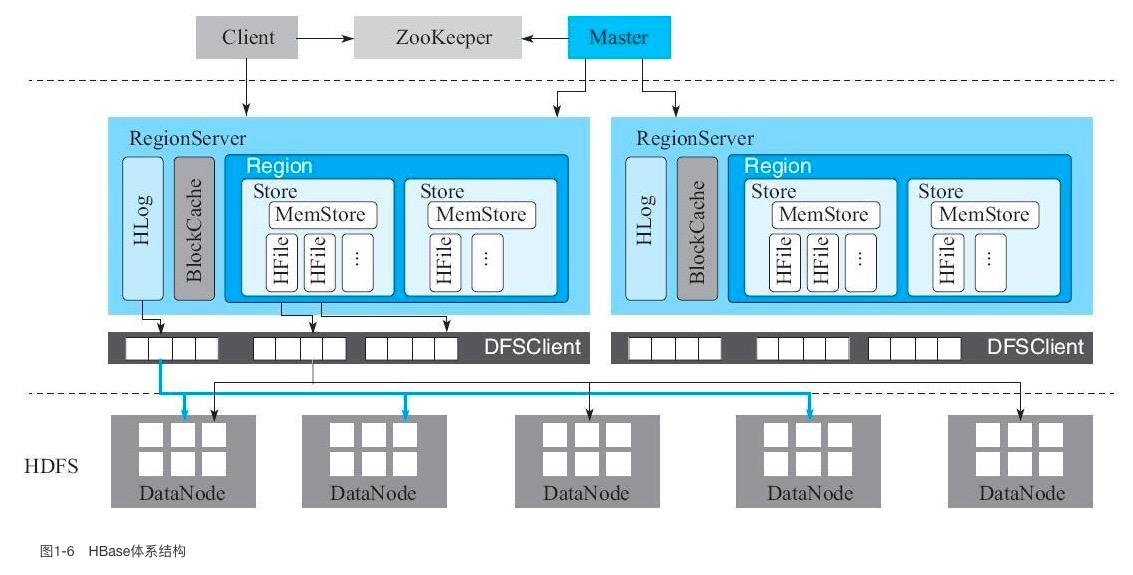
Client
- 包含访问 HBase 的接口并维护 cache 来加快对 HBase 的访问。
- HBase 客户端访问数据行之前,首先需要通过元数据表定位目标数据所在 RegionServer,之后才会发送请求到该 RegionServer。
- 同时这些元数据会被缓存在客户端本地,以方便之后的请求访问。
- 如果集群 RegionServer 发生宕机或者执行了负载均衡等,从而导致数据分片发生迁移,客户端需要重新请求最新的元数据并缓存在本地。
Zookeeper
- 保证任何时候,集群中只有一个工作状态的 master。
- 存储 HBase 的 schema 和 table 元数据。
- 存储所有 Region 的寻址入口。
- 实时监控 RegionServer 的上线和下线信息,并实时通知 Master。
- 通过心跳可以感知到 RegionServer 是否宕机,并在宕机后通知 Master 进行宕机处理。
- HBase 中对一张表进行各种管理操作(比如 alter 操作)需要先加表锁,防止其他用户对同一张表进行管理操作,造成表状态不一致。和其他 RDBMS 表不同,HBase 中的表通常都是分布式存储,ZooKeeper 可以通过特定机制实现分布式表锁。
Master
- 处理用户的各种管理请求,包括建表、修改表、权限操作、切分表、合并数据分片以及 Compaction 等。
- 管理集群中所有 RegionServer,包括为 RegionServer 分配 region,负责 RegionServer 的负载均衡、RegionServer 的宕机恢复以及 Region 的迁移等。
- 清理过期日志以及文件,Master 会每隔一段时间检查 HDFS 中 HLog 是否过期、HFile 是否已经被删除,并在过期之后将其删除。
RegionServer
- 主要用来响应用户的 IO 请求,是 HBase 中最核心的模块,由 WAL(HLog)、BlockCache 以及多个 Region 构成。
- WAL 用来保证数据写入的可靠性。
- BlockCache 可以将数据块缓存在内存中以提升数据读取性能。
- Region 是 HBase 中数据表的一个数据分片,一个 RegionServer 上通常会负责多个 Region 的数据读写。
- 一个 Region 由多个 Store 组成,每个 Store 存放对应列族的数据,比如一个表中有两个列族,这个表的所有 Region 就都会包含两个 Store。
- 每个 Store 包含一个 MemStore 和多个 HFile,用户数据写入时会将对应列族数据写入相应的 MemStore,一旦写入数据的内存大小超过设定阈值,系统就会将 MemStore 中的数据落盘形成 HFile 文件。
- HFile 存放在 HDFS 上,是一种定制化格式的数据存储文件,方便用户进行数据读取。
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!