数据结构和算法:Bloom Filter
本文最后更新于:2021年6月10日 下午
如何高效判断元素 w 是否存在于集合 A 之中?首先想到的答案是,把集合 A 中的元素一个个放到哈希表中,然后在哈希表中查一下 w 即可。但如果 A 中元素数量巨大,甚至数据量远远超过机器内存空间,该如何解决问题呢?实现一个基于磁盘和内存的哈希索引当然可以解决这个问题。而另一种低成本的方式就是借助 Bloom Filter(布隆过滤器)来实现。
简介
Bloom Filter(布隆过滤器)是一种高效利用空间的概率数据结构,由 Burton Howard Bloom 于 1970 年提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。Bloom Filter 可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
基本原理
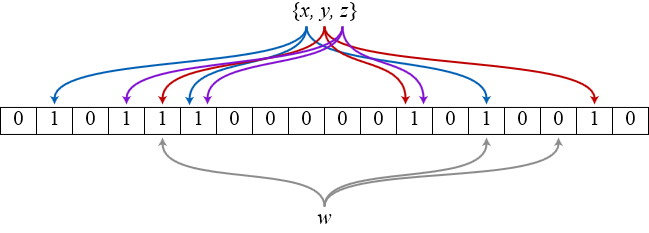
以上图为例,具体的操作流程:假设集合里面有 3 个元素 {x, y, z},哈希函数的个数为 3。
首先将位数组进行初始化,将里面每个位都设置位 0。对于集合里面的每一个元素,将元素依次通过 3 个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为 1。
查询 W 元素是否存在集合中的时候,同样的方法将 W 通过哈希映射到位数组上的 3 个点。如果 3 个点的其中有一个点不为 1,则可以判断该元素一定不存在集合中。反之,如果 3 个点都为 1,则该元素可能存在集合中。
注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为 4,5,6 这 3 个点。虽然这 3 个点都为 1,但是很明显这 3 个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是 1,这是误判率存在的原因。
缺点
Bloom Filter 基于位图的模式带来两个问题:
误报(false positives):
在查询时能提供“一定不存在”,但只能提供“可能存在”,因为存在其它元素被映射到部分相同 bit 位上,导致该位置 1,那么一个不存在的元素可能会被误报成存在。
漏报(false nagatives):
如果删除了某个元素,导致该映射 bit 位被置 0,那么本来存在的元素会被漏报成不存在。由于后者问题严重得多,所以 Bloom Filter 必须确保”definitely no”从而容忍“probably yes”,不允许元素的删除。
关于元素删除的问题,一个改良方案是对 Bloom Filter 引入计数(Counting Bloom filters),但这样一来,原来每个 bit 空间就要扩张成一个计数值,空间效率上又降低了。
在 HBase 中的应用
Bloom Filter 只需占用极小的空间,便可给出“可能存在”和“肯定不存在”的存在性判断。因此 HBase 可以在 Get 操作时通过使用 Bloom Filter 来过滤大量无效数据块,从而节省大量磁盘 IO。
HBase 中用户可以对某些列设置不同类型的 Bloom Filter,共有三种类型:
- NONE:关闭 Bloom Filter 功能。
- ROW:按照 rowkey 来计算 Bloom Filter 的二进制串并存储。Get 查询的时候,必须带 rowkey,所以用户可以在建表时默认把 Bloom Filter 设置为 ROW 类型。
- ROWCOL:按照 rowkey + family + qualifier 这 3 个字段拼出 byte[] 来计算 Bloom Filter 值并存储。如果在查询的时候,Get 能指定 rowkey、family、qualifier 这 3 个字段,则肯定可以通过 Bloom Filter 提升性能。但是如果在查询的时候,Get 中缺少 rowkey、family、qualifier 中任何一个字段,则无法通过 Bloom Filter 提升性能,因为计算 Bloom Filter 的 Key 不确定。
一般意义上的 Scan 操作,HBase 都没法使用 Bloom Filter 来提升扫描数据性能。因为此时 Bloom Filter 的 Key 值不确定,所以没法计算出哈希值对比。但是,在某些特定场景下,Scan 操作同样可以借助 Bloom Filter 提升性能。
对于 ROWCOL 类型的 Bloom Filter 来说,如果在 Scan 操作中明确指定需要扫某些列。那么在 Scan 过程中,碰到 KV 数据从一行换到新的一行时,是没法走 ROWCOL 类型 Bloom Filter 的,因为新一行的 key 值不确定;但是,如果在同一行数据内切换列时,则能通过 ROWCOL 类型 Bloom Filter 进行优化,因为 rowkey 确定,同时 column 也已知,也就是说,Bloom Filter 中的 Key 确定,所以可以通过 ROWCOL 优化性能。
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!