HBase 学习:RegionServer
本文最后更新于:2021年6月10日 下午
RegionServer 是 HBase 系统中最核心的组件,主要负责用户数据写入、读取等基础操作。RegionServer 包含多个核心模块:HLog、MemStore、HFile 以及 BlockCache。本文主要介绍 RegionServer 核心模块的作用、内部结构等内容。后续文章中将会进一步介绍 HBase 的写入读取流程。
内部结构
RegionServer 是 HBase 系统响应用户读写请求的工作节点组件,由多个核心模块组成,其内部结构如图所示。
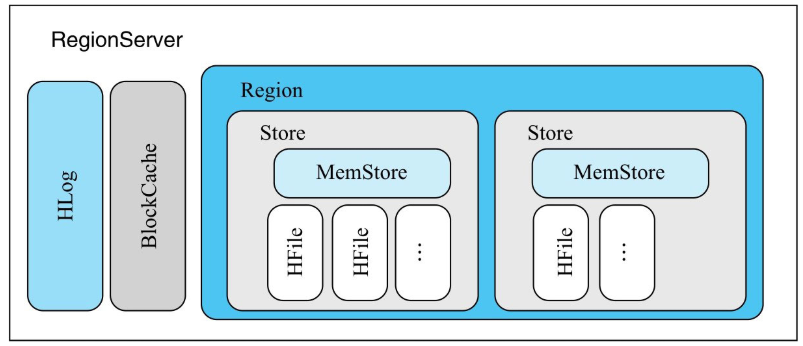
一个 RegionServer 由一个(或多个)HLog、一个 BlockCache 以及多个 Region 组成。
- HLog 用来保证数据写入的可靠性;
- BlockCache 可以将数据块缓存在内存中以提升数据读取性能;
- Region 是 HBase 中数据表的一个数据分片,一个 RegionServer 上通常会负责多个 Region 的数据读写。
- 一个 Region 由多个 Store 组成,每个 Store 存放对应列族的数据,比如一个表中有两个列族,这个表的所有 Region 就都会包含两个 Store。
- 每个 Store 包含一个 MemStore 和多个 HFile,用户数据写入时会将对应列族数据写入相应的 MemStore,一旦写入数据的内存大小超过设定阈值,系统就会将 MemStore 中的数据落盘形成 HFile 文件。HFile 存放在 HDFS 上,是一种定制化格式的数据存储文件,方便用户进行数据读取。
HLog
HBase 中系统故障恢复以及主从复制都基于 HLog 实现。默认情况下,所有写入操作(写入、更新以及删除)的数据都先以追加形式写入 HLog,再写入 MemStore。大多数情况下,HLog 并不会被读取,但如果 RegionServer 在某些异常情况下发生宕机,此时已经写入 MemStore 中但尚未 flush 到磁盘的数据就会丢失,需要回放 HLog 补救丢失的数据。此外,HBase 主从复制需要主集群将 HLog 日志发送给从集群,从集群在本地执行回放操作,完成集群之间的数据复制。
文件结构
HLog 文件的基本结构如图所示。
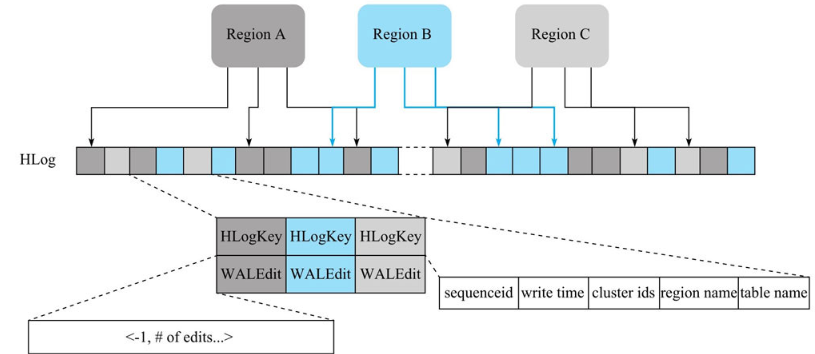
每个 RegionServer 拥有一个或多个 HLog(默认只有 1 个,1.1 版本可以开启 MultiWAL 功能,允许多个 HLog)。每个 HLog 是多个 Region 共享的,图中 Region A、Region B 和 Region C 共享一个 HLog 文件。
HLog 中,日志单元 WALEntry(图中小方框)表示一次行级更新的最小追加单元,它由 HLogKey 和 WALEdit 两部分组成,其中 HLogKey 由 table name、region name 以及 sequenceid 等字段构成。
- 为了保证行级事务的原子性,HBase 将一个行级事务的写入操作表示为一条记录。WALEdit 会被序列化为格式
<-1, # of edits, , , >,-1 为标识符,表示这种新的日志结构。假设一个行级事务更新 R 行中的 3 列(c1, c2, c3),WAL 结构为<-1, 3, <Keyvalue-for-edit-c1>, <KeyValue-for-edit-c2>, <KeyValue-for-edit-c3>>。
文件存储
HBase 中所有数据(包括 HLog 以及用户实际数据)都存储在 HDFS 的指定目录下。假设指定目录为 /hbase,/hbase/WALs 存储当前还未过期的日志;/hbase/oldWALs 存储已经过期的日志。/hbase/WALs 目录下通常会有多个子目录,每个子目录代表一个对应的 RegionServer。
生命周期
HLog 文件生成之后并不会永久存储在系统中,它的使命完成后,文件就会失效最终被删除。HLog 整个生命周期如图所示。

HLog 生命周期包含 4 个阶段:
HLog 构建:HBase 的任何写入(更新、删除)操作都会先将记录追加写入到 HLog 文件中。
HLog 滚动:HBase 后台启动一个线程,每隔一段时间(由参数
hbase.regionserver. logroll.period决定,默认 1 小时)进行日志滚动。日志滚动会新建一个新的日志文件,接收新的日志数据。日志滚动机制主要是为了方便过期日志数据能够以文件的形式直接删除。HLog 失效:写入数据一旦从 MemStore 中落盘,对应的日志数据就会失效。为了方便处理,HBase 中日志失效删除总是以文件为单位执行。查看某个 HLog 文件是否失效只需确认该 HLog 文件中所有日志记录对应的数据是否已经完成落盘,如果日志中所有日志记录已经落盘,则可以认为该日志文件失效。一旦日志文件失效,就会从 WALs 文件夹移动到 oldWALs 文件夹。注意此时 HLog 并没有被系统删除。
HLog 删除:Master 后台会启动一个线程,每隔一段时间(参数
hbase.master.cleaner. interval,默认 1 分钟)检查一次文件夹 oldWALs 下的所有失效日志文件,确认是否可以删除,确认可以删除之后执行删除操作。确认条件主要有两个:- 该 HLog 文件是否还在参与主从复制。对于使用 HLog 进行主从复制的业务,需要继续确认是否该 HLog 还在应用于主从复制。
- 该 HLog 文件是否已经在 OldWALs 目录中存在 10 分钟。为了更加灵活地管理 HLog 生命周期,系统提供了参数设置日志文件的 TTL(参数 ‘hbase.master.logcleaner.ttl’,默认 10 分钟),默认情况下 oldWALs 里面的 HLog 文件最多可以再保存 10 分钟。
HLog 中的 sequenceId 的具体作用可以参考: HBase原理-要弄懂的sequenceId。
MemStore
HBase 系统中一张表会被水平切分成多个 Region,每个 Region 负责自己区域的数据读写请求。水平切分意味着每个 Region 会包含所有的列族数据,HBase 将不同列族的数据存储在不同的 Store 中,每个 Store 由一个 MemStore 和一系列 HFile 组成。
HBase 基于 LSM 树模型实现,所有的数据写入操作首先会顺序写入日志 HLog,再写入 MemStore,当 MemStore 中数据大小超过阈值之后再将这些数据批量写入磁盘,生成一个新的 HFile 文件。LSM 树架构有如下几个非常明显的优势:
- 这种写入方式将一次随机 IO 写入转换成一个顺序 IO 写入(HLog 顺序写入)加上一次内存写入(MemStore 写入),使得写入性能得到极大提升。
- HFile 中 KeyValue 数据需要按照 Key 排序,排序之后可以在文件级别根据有序的 Key 建立索引树,极大提升数据读取效率。然而 HDFS 本身只允许顺序读写,不能更新,因此需要数据在落盘生成 HFile 之前就完成排序工作,MemStore 就是 KeyValue 数据排序的实际执行者。
- MemStore 作为一个缓存级的存储组件,总是缓存着最近写入的数据。对于很多业务来说,最新写入的数据被读取的概率会更大。
- 在数据写入 HFile 之前,可以在内存中对 KeyValue 数据进行很多更高级的优化。比如,如果业务数据保留版本仅设置为 1,在业务更新比较频繁的场景下,MemStore 中可能会存储某些数据的多个版本。这样,MemStore 在将数据写入 HFile 之前实际上可以丢弃老版本数据,仅保留最新版本数据。
内部结构
实现 MemStore 模型的数据结构是 SkipList(跳表),跳表可以实现高效的查询、插入、删除操作,这些操作的期望复杂度都是 O(logN)。HBase 使用了 JDK 自带的数据结构 ConcurrentSkipListMap,MemStore 由两个 ConcurrentSkipListMap(称为 A 和 B)实现。写入操作(包括更新删除操作)会将数据写入 ConcurrentSkipListMap A,当 ConcurrentSkipListMap A 中数据量超过一定阈值之后会创建一个新的 ConcurrentSkipListMap B 来接收用户新的请求,之前已经写满的 ConcurrentSkipListMap A 会执行异步 flush 操作落盘形成 HFile。
GC问题
对于 HBase 这样基于 LSM 实现的 MemStore 来说,上述实现方案每写入一个 KeyValue,在没有写入 ConcurrentSkipList 之前就需要申请一个内存对象,这些对象会在内存中存在很长一段时间。
又因为一个 RegionServer 由多个 Region 构成,每个 Region 根据列族的不同又包含多个 MemStore,这些 MemStore 都是共享内存的。这样,不同 Region 的数据写入对应的 MemStore,因为共享内存,在 JVM 看来所有 MemStore 的数据都是混合在一起写入 Heap 的。
一旦某个 Region 的所有 MemStore 数据执行 flush 操作,所占用的内存就会被释放。而由于其他 MemStore 数据还未执行 flush,因此释放的内存空间就变成内存碎片。这些内存空间继续为写入 MemStore 的数据分配空间,在下一次 flush 后会形成更小的内存碎片。最终因为无法分配一块完成可用的内存空间,频发触发长时间的 Full GC。
优化
MSLAB
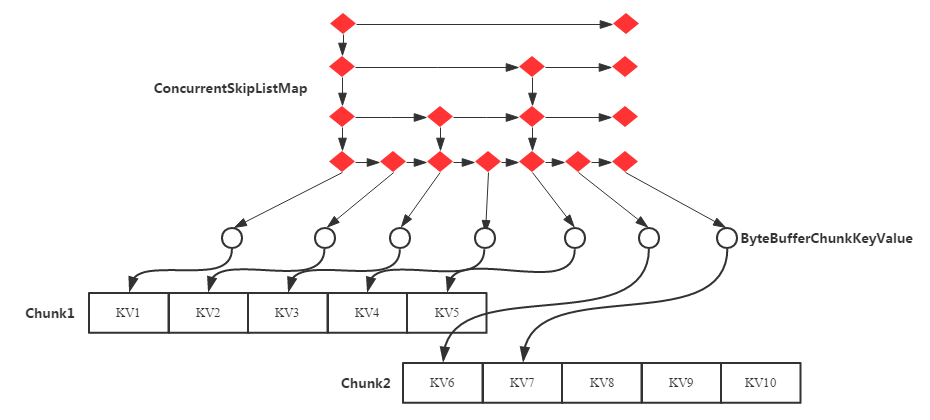
MemStore 借鉴 TLAB(Thread Local Allocation Buffer)机制,实现了 MemStoreLAB,简称 MSLAB。基于 MSLAB 实现写入的核心流程如下:
一个 KeyValue 写入之后不再单独为 KeyValue 申请内存,而是提前申请好一个 2M 大小的内存区域(Chunk)。
将写入的 KeyValue 顺序复制到申请的 Chunk 中,一旦 Chunk 写满,再申请下一个 Chunk。
将 KeyValue 复制到 Chunk 中后,生成一个 Cell 对象(这个 Cell 对象在源码中为 ByteBufferChunkKeyValue),这个 Cell 对象指向 Chunk 中的 KeyValue 内存区域。
将这个 Cell 对象作为 Key 和 Value 写入 ConcurrentSkipListMap 中。
原生的 KeyValue 对象写入到 Chunk 之后就没有再被引用,所以很快就会被 Young GC 回收掉。
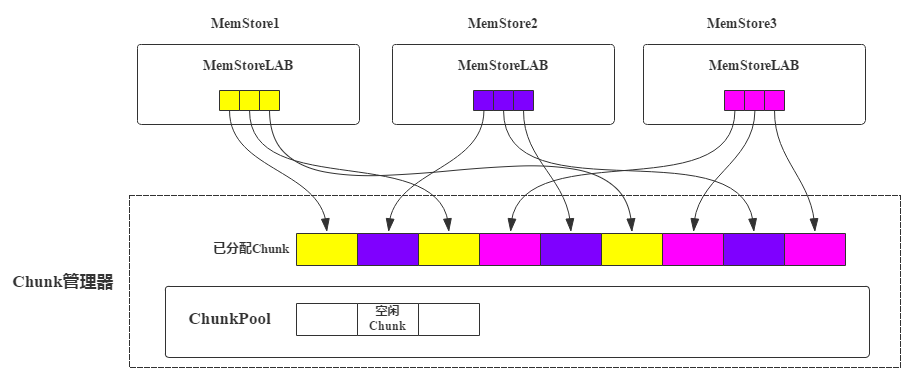
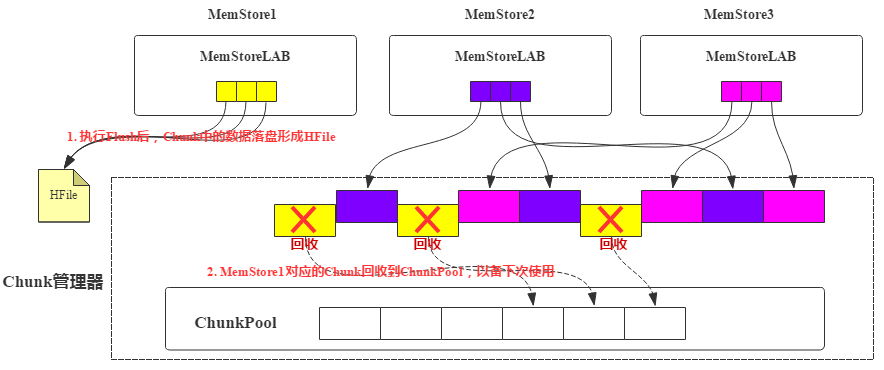
ChunkPool
MSLAB 机制中 KeyValue 写入 Chunk,如果 Chunk 写满了会在 JVM 堆内存申请一个新的 Chunk。引入 ChunkPool 后,申请 Chunk 都从 ChunkPool 中申请,如果 ChunkPool 中没有可用的空闲 Chunk,才会从 JVM 堆内存中申请新 Chunk。如果一个 MemStore 执行 flush 操作后,这个 MemStore 对应的所有 Chunk 都可以被回收,回收后重新进入池子中,以备下次使用。
每个 RegionServer 会有一个全局的 Chunk 管理器,负责 Chunk 的生成、回收等。MemStore 申请 Chunk 对象会发送请求让 Chunk 管理器创建新 Chunk,Chunk 管理器会检查当前是否有空闲 Chunk,如果有空闲 Chunk,就会将这个 Chunk 对象分配给 MemStore,否则从 JVM 堆上重新申请。每个 MemStore 仅持有 Chunk 内存区域的引用
Chunk Offheap
HBase 2.0 为了尽最大可能避免 Java GC 对其造成的性能影响,已经对读写两条核心路径做了 offheap 化,也就是对象的申请都直接向 JVM offheap 申请,而 offheap 分出来的内存都是不会被 JVM GC 的,需要用户自己显式地释放。在写路径上,客户端发过来的请求包都会被分配到 offheap 的内存区域,直到数据成功写入 WAL 日志和 Memstore,其中维护 Memstore 的 ConcurrentSkipListSet 其实也不是直接存 Cell 数据,而是存 Cell 的引用,真实的内存数据被编码在 MSLAB 的多个 Chunk 内,这样比较便于管理 offheap 内存。类似地,在读路径上,先尝试去读 BucketCache,Cache 未命中时则去 HFile 中读对应的 Block,这其中占用内存最多的 BucketCache 就放在 offheap 上,拿到 Block 后编码成 Cell 发送给用户,整个过程基本上都不涉及 heap 内对象申请。
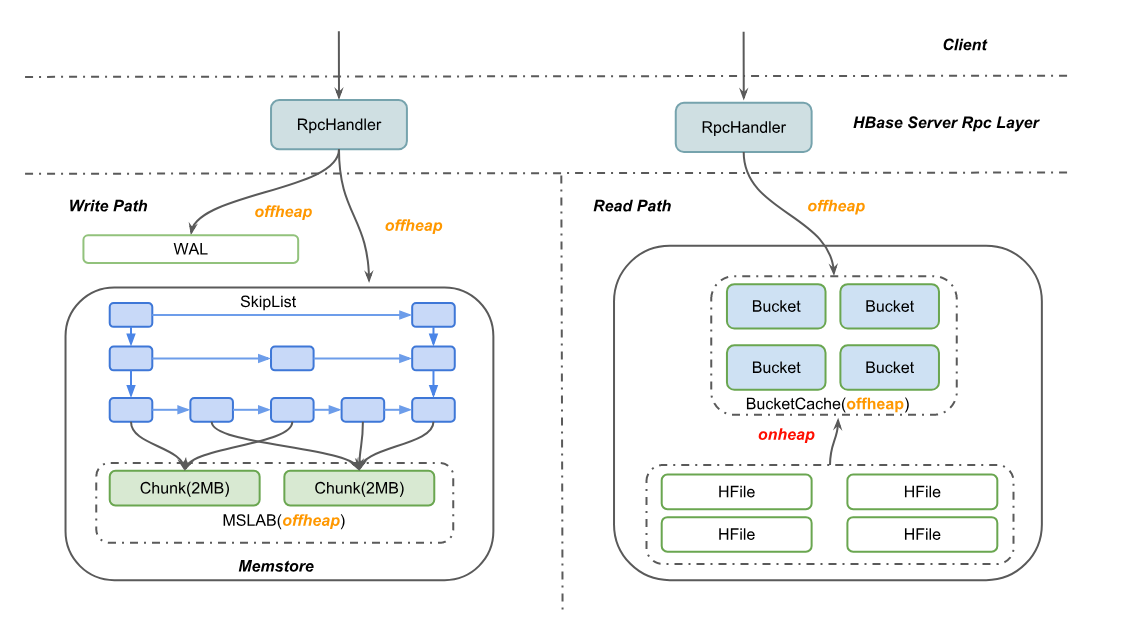
Chunk 堆外化实现比较简单,在创建新 Chunk 时根据用户配置选择是否使用堆外内存,如果使用堆外内存,就使用 JDK 提供的 ByteBuffer.allocateDirect 方法在堆外申请特定大小的内存区域,否则使用 ByteBuffer.allocate 方法在堆内申请。如果不做配置,默认使用堆内内存,用户可以设置 hbase.regionserver.offheap.global.memstore.size 这个值为大于 0 的值开启堆外,表示 RegionServer 中所有 MemStore 可以使用的堆外内存总大小。
In-memory Compaction
In-Memory Compaction 是 HBase2.0 中的重要特性之一,通过在内存中引入 LSM tree 结构,减少多余数据,实现降低 flush 频率和减小写放大的效果。
In-Memory Compaction 中引入了 MemStore 的一个新的实现类 CompactingMemStore 。在默认的 MemStore 中,对 Cell 的索引使用 ConcurrentSkipListMap,这种结构支持动态修改,但是其中存在大量小对象,内存浪费比较严重。而在 CompactingMemStore 中,MemStore 分为 MutableSegment 和 ImmutableSegment,其中 ImmutableSegment 就可以使用更紧凑的数据结构来存储索引,减少内存使用。
CompactingMemStore 的核心工作原理如图所示:
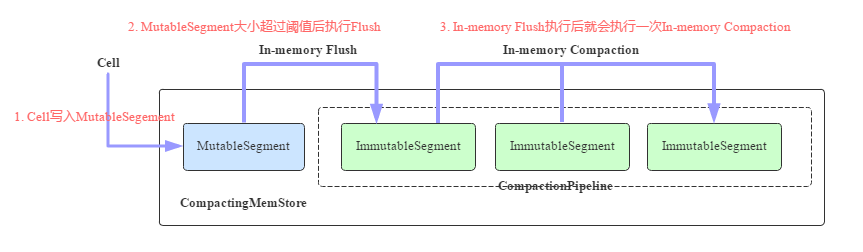
- 一个 Cell 写入到 Region 后会先写 入 MutableSegment 中。MutableSegment 可以认为就是一个小的 MemStore,MutableSegment 包含一个 MSLAB 存储 Chunk,同时包含一个 ConcurrentSkipListMap。
- 默认情况下一旦 MutableSegment 的大小超过 2M,就会执行 In-memory Flush 操作,将 MutableSegment 变为 ImmutableSegment,并重新生成一个新的 MutableSegment 接收写入。ImmutableSegment 有多个实现类,In-memory Flush 生成的 ImmutableSegment 为 CSLMImmutableSegment,可以预见这个 ImmutableSegment 在数据结构上也是使用 ConcurrentSkipListMap。
- 每次执行完 In-memory Flush 之后,RegionServer 都会启动一个异步线程执行 In-memory Compaction。In-memory Compaction 的本质是将 CSLMImmutableSegment 变为 CellArrayImmutableSegment 或者 CellChunkImmutableSegment。
CellArrayImmutableSegment 和 CSLMImmutableSegment 相比,相当于将 ConcurrentSkipListMap 拉平为数组。CellChunkImmutableSegment 借鉴 Chunk 思路申请一块 2M 的大内存空间,遍历数组中的 Cell 对象,将其顺序拷贝到这个 Chunk(这种 Chunk 称为 Index Chunk,区别与存储 KV 数据的 Data Chunk)中,就变成了 CellChunkImmutableSegment。
如果 RegionServer 需要把 MemStore 的数据 flush 到磁盘,会首先选择其他类型 的 MemStore,然后再选择 CompactingMemStore。这是因为 CompactingMemStore 对内存的管理更有效率,所以延长 CompactingMemStore 的生命周期可以减少总的 I/O。当 CompactingMemStore 被 flush 到磁盘时, 所有 segment 会被移到一个 snapshot 中进行合并然后写入 HFile。
HFile
HFile 是 HBase 存储数据的文件组织形式,参考 BigTable 的 SSTable 和 Hadoop 的 TFile 实现。从 HBase 开始到现在,HFile 经历了三个版本,其中 V2 在 0.92 引入,V3 在 0.98 引入。HFile V1 版本的在实际使用过程中发现它占用内存多,HFile V2 版本针对此进行了优化,HFile V3 版本基本和 V2 版本相同,只是在 cell 层面添加了 Tag 数组的支持。
逻辑结构
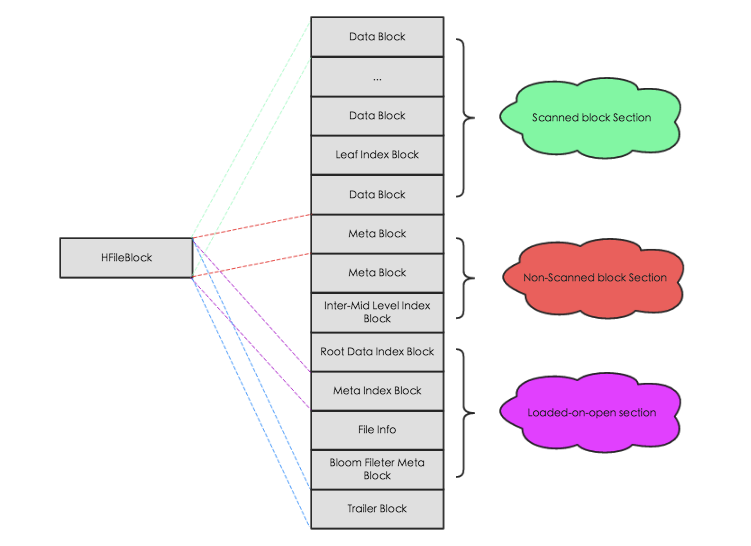
HFile V2 的逻辑结构如下图所示:
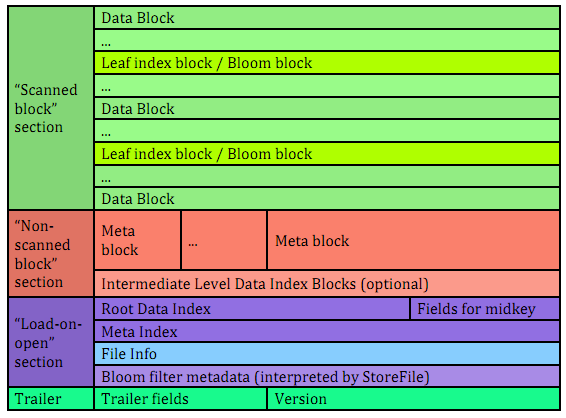
文件主要分为四个部分:Scanned block section,Non-scanned block section,Opening-time data section 和 Trailer。
Scanned block section:顾名思义,表示顺序扫描 HFile 时所有的数据块将会被读取,包括 Leaf Index Block 和 Bloom Block。
Non-scanned block section:表示在 HFile 顺序扫描的时候数据不会被读取,主要包括 Meta Block 和 Intermediate Level Data Index Blocks 两部分。
Load-on-open-section:这部分数据在 HBase 的 region server 启动时,需要加载到内存中。包括 FileInfo、Bloom filter block、data block index 和 meta block index。
Trailer:这部分主要记录了 HFile 的基本信息、各个部分的偏移值和寻址信息。
物理结构
如上图所示, HFile 会被切分为多个大小相等的 block 块,每个 block 的大小可以在创建表列族的时候通过参数 blocksize => ‘65535’ 进行指定,默认为 64k,大号的 Block 有利于顺序 Scan,小号 Block 利于随机查询,因而需要权衡。而且所有 block 块都拥有相同的数据结构,如下图左侧所示,HBase 将 block 块抽象为一个统一的 HFileBlock。HFileBlock 支持两种类型,一种类型不支持 checksum,一种不支持。为方便讲解,下图选用不支持 checksum 的 HFileBlock 内部结构:
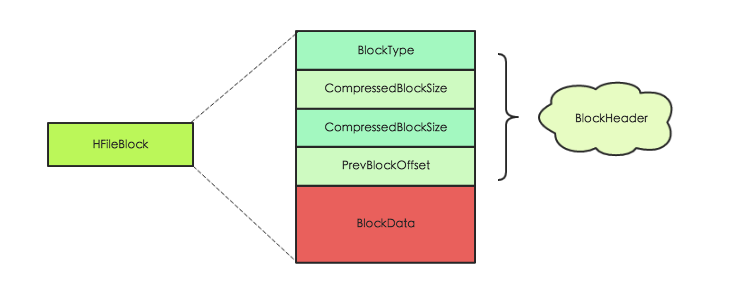
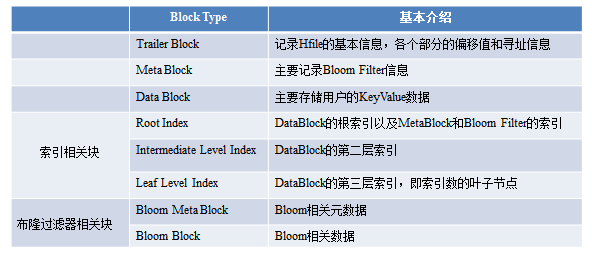
上图所示 HFileBlock 主要包括两部分:BlockHeader 和 BlockData。其中 BlockHeader 主要存储 block 元数据,BlockData 用来存储具体数据。block 元数据中最核心的字段是 BlockType 字段,用来标示该 block 块的类型,HBase 中定义了 8 种 BlockType,每种 BlockType 对应的 block 都存储不同的数据内容,有的存储用户数据,有的存储索引数据,有的存储 meta 元数据。对于任意一种类型的 HFileBlock,都拥有相同结构的 BlockHeader,但是 BlockData 结构却不相同。下面通过一张表简单罗列最核心的几种 BlockType,下文会详细针对每种 BlockType 进行详细的讲解:
Block块解析
Trailer Block
主要记录了 HFile 的基本信息、各个部分的偏移值和寻址信息,下图为 Trailer 内存和磁盘中的数据结构,其中只显示了部分核心字段:

HFile 在读取的时候首先会解析 Trailer Block 并加载到内存,然后再进一步加载 LoadOnOpen 区的数据,具体步骤如下:
首先加载 version 版本信息,HBase 中 version 包含 majorVersion 和 minorVersion 两部分,前者决定了 HFile 的主版本: V1、V2 还是 V3;后者在主版本确定的基础上决定是否支持一些微小修正,比如是否支持 checksum 等。不同的版本决定了使用不同的 Reader 对象对 HFile 进行读取解析。
根据 Version 信息获取 trailer 的长度(不同 version 的 trailer 长度不同),再根据 trailer 长度加载整个 HFileTrailer Block。
最后加载 load-on-open 部分到内存中,起始偏移地址是 trailer 中的 LoadOnOpenDataOffset 字段,load-on-open 部分的结束偏移量为 HFile 长度减去 Trailer 长度,load-on-open 部分主要包括索引树的根节点以及 FileInfo 两个重要模块,FileInfo 是固定长度的块,它纪录了文件的一些 Meta 信息,例如:AVG_KEY_LEN,AVG_VALUE_LEN,LAST_KEY, COMPARATOR,MAX_SEQ_ID_KEY 等。
Data Block
DataBlock 是 HBase 中数据存储的最小单元。DataBlock 中主要存储用户的 KeyValue 数据(KeyValue 后面一般会跟一个 timestamp,图中未标出),而 KeyValue 结构是 HBase 存储的核心,每个数据都是以 KeyValue 结构在 HBase 中进行存储。KeyValue 结构在内存和磁盘中可以表示为:
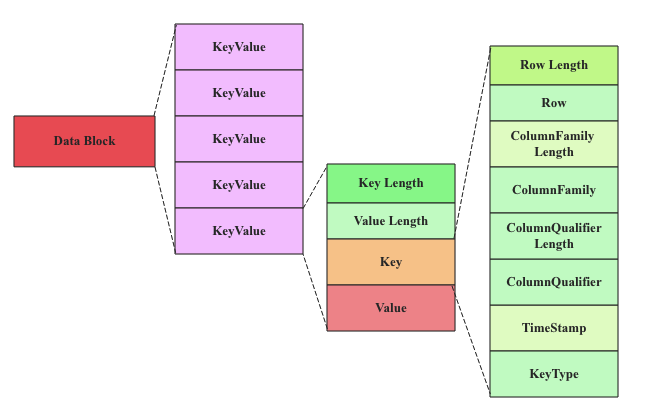
每个 KeyValue 都由 4 个部分构成,分别为 key length,value length,key 和 value。其中 key value 和 value length 是两个固定长度的数值,而 key 是一个复杂的结构,首先是 rowkey 的长度,接着是 rowkey,然后是 ColumnFamily 的长度,再是 ColumnFamily,之后是 ColumnQualifier,最后是时间戳和 KeyType(keytype 有四种类型,分别是 Put、Delete、 DeleteColumn 和 DeleteFamily),value 就没有那么复杂,就是一串纯粹的二进制数据。
Root Index Block
Root Index Block 表示索引树根节点索引块,可以作为 bloom 的直接索引,也可以作为 data 索引的根索引。而且对于 single-level 和 mutil-level 两种索引结构对应的 Root Index Block 略有不同,本文以 mutil-level 索引结构为例进行分析(single-level 索引结构是 mutual-level 的一种简化场景),在内存和磁盘中的格式如下图所示:
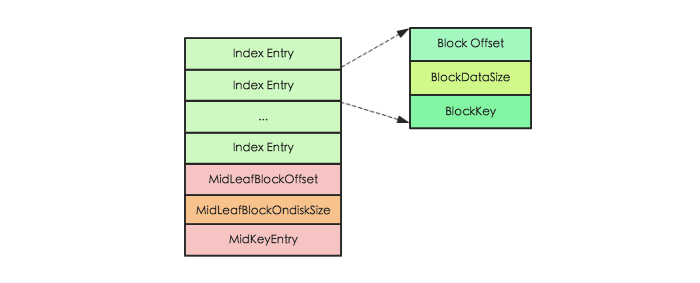
其中 Index Entry 表示具体的索引对象,每个索引对象由 3 个字段组成,Block Offset 表示索引指向数据块的偏移量,BlockDataSize 表示索引指向数据块在磁盘上的大小,BlockKey 表示索引指向数据块中的第一个 key。除此之外,还有另外 3 个字段用来记录 MidKey 的相关信息,MidKey 表示 HFile 所有 Data Block 中中间的一个 Data Block,用于在对 HFile 进行 split 操作时,快速定位 HFile 的中间位置。需要注意的是 single-level 索引结构和 mutil-level 结构相比,就只缺少 MidKey 这三个字段。
Root Index Block 会在 HFile 解析的时候直接加载到内存中,此处需要注意在 Trailer Block 中有一个字段为 dataIndexCount,就表示此处 Index Entry 的个数。因为 Index Entry 并不定长,只有知道 Entry 的个数才能正确的将所有 Index Entry 加载到内存。
InterMediate Index Block & Ieaf Index Block
当 HFile 中 Data Block 越来越多,single-level 结构的索引已经不足以支撑所有数据都加载到内存,需要分化为 mutil-level 结构。mutil-level 结构中 NonRoot Index Block 作为中间层节点或者叶子节点存在,无论是中间节点还是叶子节点,其都拥有相同的结构,如下图所示:
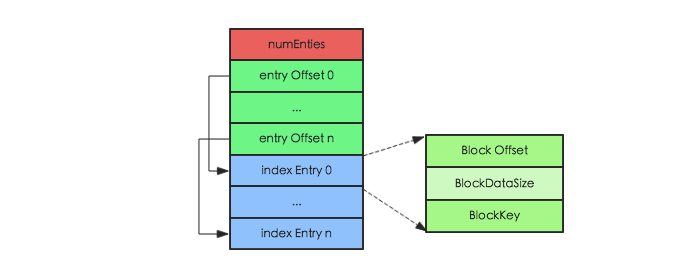
和 Root Index Block 相同,NonRoot Index Block 中最核心的字段也是 Index Entry,用于指向叶子节点块或者数据块。不同的是,NonRoot Index Block 结构中增加了 block 块的内部索引 entry Offset 字段,entry Offset 表示 index Entry 在该 block 中的相对偏移量(相对于第一个 index Entry),用于实现 block 内的二分查找。所有非根节点索引块,包括 Intermediate index block 和 leaf index block,在其内部定位一个 key 的具体索引并不是通过遍历实现,而是使用二分查找算法,这样可以更加高效快速地定位到待查找 key。
BloomFilter Meta Block & Bloom Block
HBase 中每个 HFile 都有对应的 BloomFilter 位数组,KeyValue 在写入 HFile 时会先经过几个 hash 函数的映射,映射后将对应的数组位改为 1,get 请求进来之后再进行 hash 映射,如果在对应数组位上存在 0,说明该 get 请求查询的数据不在该 HFile 中。
HFile 中的位数组就是上述 Bloom Block 中存储的值,可以想象,一个 HFile 文件越大,里面存储的 KeyValue 值越多,位数组就会相应越大。一旦太大就不适合直接加载到内存了,因此 HFile V2 在设计上将位数组进行了拆分,拆成了多个独立的位数组(根据 Key 进行拆分,一部分连续的 Key 使用一个位数组)。这样一个 HFile 中就会包含多个位数组,根据 Key 进行查询,首先会定位到具体的某个位数组,只需要加载此位数组到内存进行过滤即可,减少了内存开支。
在结构上每个位数组对应 HFile 中一个 Bloom Block,为了方便根据 Key 定位具体需要加载哪个位数组,HFile V2 又设计了对应的索引 Bloom Index Block,对应的内存和逻辑结构图如下:
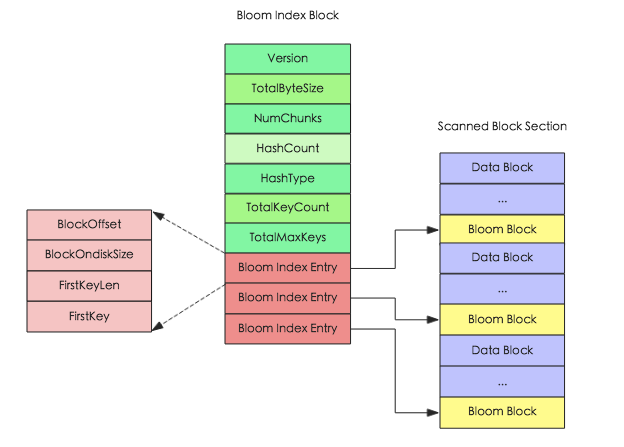
Bloom Index Block 结构中 totalByteSize 表示位数组的 bit 数,numChunks 表示 Bloom Block 的个数,hashCount 表示 hash 函数的个数,hashType 表示 hash 函数的类型,totalKeyCount 表示 bloom filter 当前已经包含的 key 的数目,totalMaxKeys 表示 bloom filter 当前最多包含的 key 的数目,Bloom Index Entry 对应每一个 bloom filter block 的索引条目,作为索引分别指向 ’scanned block section’ 部分的 Bloom Block,Bloom Block 中就存储了对应的位数组。
Bloom Index Entry 的结构见上图左边所示,BlockOffset 表 示对应 Bloom Block 在 HFile 中的偏移量,FirstKey 表示对应 BloomBlock 的第一个 Key。根据上文所说,一次 get 请求进来,首先会根据 key 在所有的索引条目中进行二分查找,查找到对应的 Bloom Index Entry,就可以定位到该 key 对应的位数组,加载到内存进行过滤判断。
BlockCache
为了提升读取性能,HBase 也实现了一种读缓存结构 BlockCache。客户端读取某个 Block,首先会检查该 Block 是否存在于 BlockCache,如果存在就直接加载出来,如果不存在则去 HFile 文件中加载,加载出来之后放到 BlockCache 中,后续同一请求或者邻近数据查找请求可以直接从内存中获取,以避免昂贵的 IO 操作。
BlockCache 是 Region Server 级别的,一个 Region Server 只有一个 BlockCache,在 RegionServer 启动的时候完成 BlockCache 的初始化工作。到目前为止,HBase 先后实现了 3 种 Block Cache 方案,LRUBlockCache 是最初的实现方案,也是默认的实现方案;HBase 0.92 版本实现了第二种方案 SlabCache;HBase 0.96 之后官方提供了另一种可选方案 BucketCache。
这三种方案的不同之处在于对内存的管理模式,其中 LRUBlockCache 是将所有数据都放入 JVM Heap 中,交给 JVM 进行管理。而后两者采用了不同机制将部分数据存储在堆外,交给 HBase 自己管理。这种演变过程是因为 LRUBlockCache 方案中 JVM 垃圾回收机制经常会导致程序长时间暂停,而采用堆外内存对数据进行管理可以有效避免这种情况发生。
LRUBlockCache
HBase 默认的 BlockCache 实现方案。Block 数据块都存储在 JVM heap 内,由 JVM 进行垃圾回收管理。它将内存从逻辑上分为了三块:single-access 区、mutil-access 区、in-memory 区,分别占到整个 BlockCache 大小的 25%、50%、25%。一次随机读中,一个 Block 块从 HDFS 中加载出来之后首先放入 signle 区,后续如果有多次请求访问到这块数据的话,就会将这块数据移到 mutil-access 区。而 in-memory 区表示数据可以常驻内存,一般用来存放访问频繁、数据量小的数据,比如元数据,用户也可以在建表的时候通过设置列族属性 IN-MEMORY= true 将此列族放入 in-memory 区。很显然,这种设计策略类似于 JVM 中 young 区、old 区以及 perm 区。无论哪个区,系统都会采用严格的 Least-Recently-Used 算法,当 BlockCache 总量达到一定阈值之后就会启动淘汰机制,最少使用的 Block 会被置换出来,为新加载的 Block 预留空间。
SlabCache
为了解决 LRUBlockCache 方案中因为 JVM 垃圾回收导致的服务中断,SlabCache 方案使用 Java NIO DirectByteBuffer 技术实现了堆外内存存储,不再由 JVM 管理数据内存。默认情况下,系统在初始化的时候会分配两个缓存区,分别占整个 BlockCache 大小的 80%和 20%,每个缓存区分别存储固定大小的 Block 块,其中前者主要存储小于等于 64K 大小的 Block,后者存储小于等于 128K Block,如果一个 Block 太大就会导致两个区都无法缓存。和 LRUBlockCache 相同,SlabCache 也使用 Least-Recently-Used 算法对过期 Block 进行淘汰。和 LRUBlockCache 不同的是,SlabCache 淘汰 Block 的时候只需要将对应的 bufferbyte 标记为空闲,后续 cache 对其上的内存直接进行覆盖即可。
线上集群环境中,不同表不同列族设置的 BlockSize 都可能不同,很显然,默认只能存储两种固定大小 Block 的 SlabCache 方案不能满足部分用户场景,比如用户设置 BlockSize = 256K,简单使用 SlabCache 方案就不能达到这部分 Block 缓存的目的。因此 HBase 实际实现中将 SlabCache 和 LRUBlockCache 搭配使用,称为 DoubleBlockCache。一次随机读中,一个 Block 块从 HDFS 中加载出来之后会在两个 Cache 中分别存储一份;缓存读时首先在 LRUBlockCache 中查找,如果 Cache Miss 再在 SlabCache 中查找,此时如果命中再将该 Block 放入 LRUBlockCache 中。
经过实际测试,DoubleBlockCache 方案有很多弊端。比如 SlabCache 设计中固定大小内存设置会导致实际内存使用率比较低,而且使用 LRUBlockCache 缓存 Block 依然会因为 JVM GC 产生大量内存碎片。因此在 HBase 0.98 版本之后,该方案已经被不建议使用。
BucketCache
SlabCache 方案在实际应用中并没有很大程度改善原有 LRUBlockCache 方案的 GC 弊端,还额外引入了诸如堆外内存使用率低的缺陷。然而它的设计并不是一无是处,至少在使用堆外内存这个方面给予了阿里大牛们很多启发。站在 SlabCache 的肩膀上,他们开发了 BucketCache 缓存方案并贡献给了社区。
BucketCache 通过配置可以工作在三种模式下:heap,offheap 和 file。无论工作在那种模式下,BucketCache 都会申请许多带有固定大小标签的 Bucket,和 SlabCache 一样,一种 Bucket 存储一种指定 BlockSize 的数据块,但和 SlabCache 不同的是,BucketCache 会在初始化的时候申请 14 个不同大小的 Bucket,而且即使在某一种 Bucket 空间不足的情况下,系统也会从其他 Bucket 空间借用内存使用,不会出现内存使用率低的情况。接下来再来看看不同工作模式,heap 模式表示这些 Bucket 是从 JVM Heap 中申请,offheap 模式使用 DirectByteBuffer 技术实现堆外内存存储管理,而 file 模式使用类似 SSD 的高速缓存文件存储数据块。
实际实现中,HBase 将 BucketCache 和 LRUBlockCache 搭配使用,称为 CombinedBlockCache。和 DoubleBlockCache 不同,系统在 LRUBlockCache 中主要存储 Index Block 和 Bloom Block,而将 Data Block 存储在 BucketCache 中。因此一次随机读需要首先在 LRUBlockCache 中查到对应的 Index Block,然后再到 BucketCache 查找对应数据块。BucketCache 通过更加合理的设计修正了 SlabCache 的弊端,极大降低了 JVM GC 对业务请求的实际影响,但也存在一些问题,比如使用堆外内存会存在拷贝内存的问题,一定程度上会影响读写性能。
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!