HBase 学习:写入流程
本文最后更新于:2021年6月10日 下午
本文介绍了 HBase 中写数据的接口和方式,数据路由和分发,以及 RegionServer 侧将数据写入到 Region 中的全部流程。
客户端接口
HBase 服务端并没有提供 update、delete 接口,HBase 中对数据的更新、删除操作在服务器端也认为是写入操作,不同的是,更新操作会写入一个最新版本数据,删除操作会写入一条标记为 deleted 的 KV 数据。所以 HBase 中更新、删除操作的流程与写入流程完全一致。
HBase 中提供了如下几种主要的接口:
Java Client API:HBase 的基础 API,应用最为广泛。
HBase Shell:基于 Shell 的命令行操作接口,基于 Java Client API 实现。
Restful API:Rest Server 侧基于 Java Client API 实现。
Thrift API:Thrift Server 侧基于 Java Client API 实现。
MapReduce Based Batch Manipulation API:基于 MapReduce 的批量数据读写 API。
除了上述主要的 API,HBase 还提供了基于 Spark 的批量操作接口以及 C++ Client 接口,但这两个特性都被规划在了 3.0 版本中,当前尚在开发中。
无论是 HBase Shell/Restful API 还是 Thrift API,都是基于 Java Client API 实现的。因此,接下来关于流程的介绍,都是基于 Java Client API 的调用流程展开的。
表服务接口抽象
HBase 支持同步连接与异步连接,分别提供了不同的表服务接口抽象:
Table:同步连接中的表服务接口定义
AsyncTable:异步连接中的表服务接口定义
异步连接 AsyncConnection 获取 AsyncTable 实例的接口默认实现:
default AsyncTable<AdvancedScanResultConsumer> getTable(TableName tableName) {
return getTableBuilder(tableName).build();
}同步连接 ClusterConnection 的实现类 ConnectionImplementation 中获取 Table 实例的接口实现:
@Override
public Table getTable(TableName tableName) throws IOException {
return getTable(tableName, getBatchPool());
}写数据方式
Single Put
单条记录单条记录的随机 put 操作。Single Put 所对应的接口定义如下:
在 AsyncTable 接口中的定义:
CompletableFuture<Void> put(Put put);在 Table 接口中的定义:
void put(Put put) throws IOException;Batch Put
汇聚了几十条甚至是几百上千条记录之后的小批次随机 put 操作。
Batch Put 只是本文对该类型操作的称法,实际的接口名称如下所示:
在 AsyncTable 接口中的定义:
List<CompletableFuture<Void>> put(List<Put> puts);在 Table 接口中的定义:
void put(List<Put> puts) throws IOException;Bulkload
基于 MapReduce API 提供的数据批量导入能力,导入数据量通常在 GB 级别以上,Bulkload 能够绕过 Java Client API 直接生成 HBase 的底层数据文件(HFile)。
客户端处理阶段
数据路由
初始化 ZooKeeper Session
因为 meta Region 的路由信息存放于 ZooKeeper 中,在第一次从 ZooKeeper 中读取 META Region 的地址时,需要先初始化一个 ZooKeeper Session。ZooKeeper Session 是 ZooKeeper Client 与 ZooKeeper Server 端所建立的一个会话,通过心跳机制保持长连接。
获取 Region 路由信息
通过前面建立的连接,从 ZooKeeper 中读取 meta Region 所在的 RegionServer,这个读取流程,当前已经是异步的。获取了 meta Region 的路由信息以后,再从 meta Region 中定位要读写的 RowKey 所关联的 Region 信息。如下图所示:
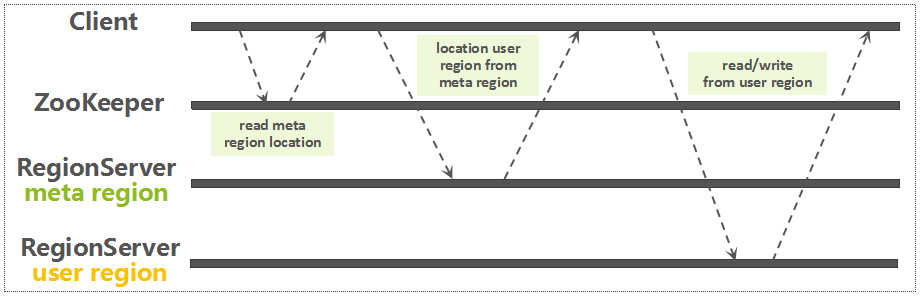
因为每一个用户表 Region 都是一个 RowKey Range,meta Region 中记录了每一个用户表 Region 的路由以及状态信息,以 RegionName(包含表名,Region StartKey,Region ID,副本 ID 等信息)作为 RowKey。基于一条用户数据 RowKey,快速查询该 RowKey 所属的 Region 的方法其实很简单:只需要基于表名以及该用户数据 RowKey,构建一个虚拟的 Region Key,然后通过 Reverse Scan 的方式,读到的第一条 Region 记录就是该数据所关联的 Region。如下图所示:

Region 只要不被迁移,那么获取的该 Region 的路由信息就是一直有效的,因此,HBase Client 有一个 Cache 机制来缓存 Region 的路由信息,避免每次读写都要去访问 ZooKeeper 或者 meta Region。
客户端的写缓冲区
用户提交 put 请求后,HBase 客户端会将写入的数据添加到本地缓冲区中,符合一定条件就会通过 AsyncProcess 异步批量提交。HBase 默认设置 autoflush=true,表示 put 请求直接会提交给服务器进行处理;用户可以设置 autoflush=false,这样,put 请求会首先放到本地缓冲区,等到本地缓冲区大小超过一定阈值(默认为 2M,可以通过配置文件配置)之后才会提交。很显然,后者使用批量提交请求,可以极大地提升写入吞吐量,但是因为没有保护机制,如果客户端崩溃,会导致部分已经提交的数据丢失。
客户端的数据分组
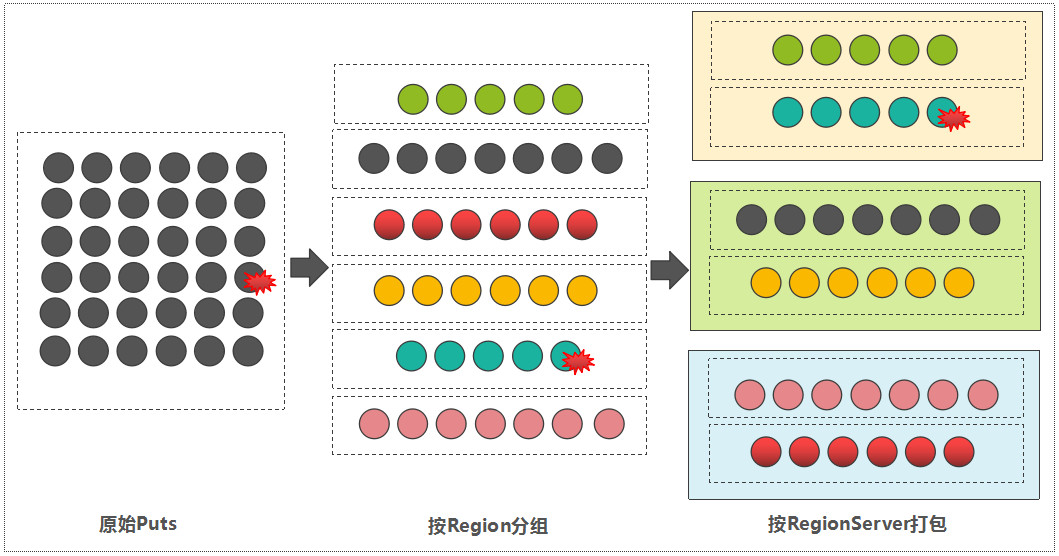
如果待写入的数据采用 Batch Put 的方式,那么,客户端在将所有的数据写到对应的 RegionServer 之前,会先分组,流程如下:
- 遍历每一条数据的 RowKey,然后,依据 meta 表中记录的 Region 信息,确定每一条数据所属的 Region。此步骤可以获取到 Region 到 RowKey 列表的映射关系。
- 因为 Region 一定归属于某一个 RegionServer(未考虑 Region Replica 特性),那属于同一个 RegionServer 的多个 Regions 的写入请求,被打包成一个 MultiAction 对象,这样可以一并发送到每一个 RegionServer 中。
客户端发送写数据请求
HBase 会为每个 HRegionLocation 构造一个远程 RPC 请求 MultiServerCallable,并通过 rpcCallerFactory.newCaller()执行调用。将请求经过 Protobuf 序列化后发送给对应的 RegionServer。
Region 写入阶段
Region 分发
RegionServer 的 RPC Server 侧,接收到来自 Client 端的 RPC 请求以后,将该请求交给 Handler 线程处理。
如果是 single put,则该步骤比较简单,因为在发送过来的请求参数 MutateRequest 中,已经携带了这条记录所关联的 Region,那么直接将该请求转发给对应的 Region 即可。
如果是 batch puts,则接收到的请求参数为 MultiRequest,在 MultiRequest 中,混合了这个 RegionServer 所持有的多个 Region 的写入请求,每一个 Region 的写入请求都被包装成了一个 RegionAction 对象。RegionServer 接收到 MultiRequest 请求以后,遍历所有的 RegionAction,而后写入到每一个 Region 中,此过程是串行的。
核心操作
服务器端 RegionServer 接收到客户端的写入请求后,首先会反序列化为 put 对象,然后执行各种检查操作,比如检查 Region 是否是只读、MemStore 大小是否超过 blockingMemstoreSize 等。检查完成之后,执行一系列核心操作。
- Acquire locks:HBase 中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么更新失败。
- Update LATEST_TIMESTAMP timestamps:更新所有待写入(更新)KeyValue 的时间戳为当前系统时间。
- Build WAL edit:HBase 使用 WAL 机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复 HLog 还原出原始数据。该步骤就是在内存中构建 WALEdit 对象,为了保证 Region 级别事务的写入原子性,一次写入操作中所有 KeyValue 会构建成一条 WALEdit 记录。
- Append WALEdit To WAL:将步骤 3 中构造在内存中的 WALEdit 记录顺序写入 HLog 中,此时不需要执行 sync 操作。当前版本的 HBase 使用了 disruptor 实现了高效的生产者消费者队列,来实现 WAL 的追加写入操作。
- Write back to MemStore:写入 WAL 之后再将数据写入 MemStore。
- Release row locks:释放行锁。
- Sync wal:HLog 真正 sync 到 HDFS,在释放行锁之后执行 sync 操作是为了尽量减少持锁时间,提升写性能。如果 sync 失败,执行回滚操作将 MemStore 中已经写入的数据移除。
- 结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。
写 WAL
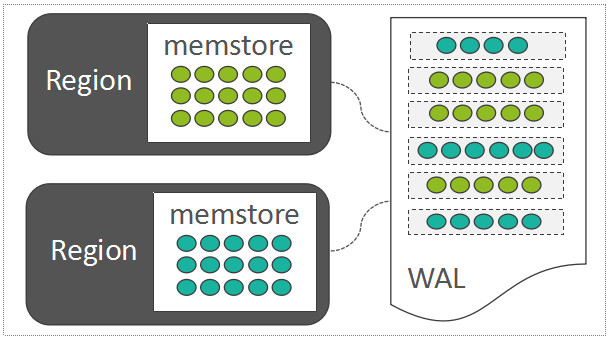
HBase 采用了 LSM-Tree 的架构设计,每一个 Region 中随机写入的数据,都暂时先缓存在内存中(HBase 中存放这部分内存数据的模块称之为 MemStore),为了保障数据可靠性,将这些随机写入的数据顺序写入到一个称之为 WAL(Write-Ahead-Log)的日志文件中,WAL 中的数据按时间顺序组织:
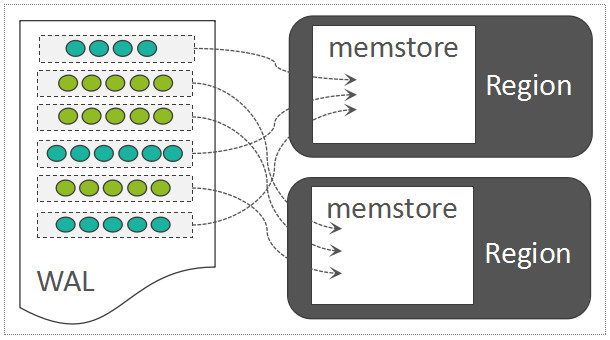
如果位于内存中的数据尚未持久化,而且突然遇到了机器断电,只需要将 WAL 中的数据回放到 Region 中即可:
在 HBase 中,默认一个 RegionServer 只有一个可写的 WAL 文件。WAL 中写入的记录,以 Entry 为基本单元,而一个 Entry 中,包含:
- WALKey:包含{Encoded Region Name,Table Name,Sequence ID,Timestamp}等关键信息,其中,Sequence ID 在维持数据一致性方面起到了关键作用,可以理解为一个事务 ID。
- WALEdit:保存待写入数据的所有的 KeyValues,而这些 KeyValues 可能来自一个 Region 中的多行数据。
WAL 持久化等级
HBase 可以通过设置持久化等级决定是否开启 WAL 机制以及 WAL 的落盘方式。持久化等级分为如下五个等级。
- SKIP_WAL:只写缓存,不写 HLog 日志。因为只写内存,因此这种方式可以极大地提升写入性能,但是数据有丢失的风险。在实际应用过程中并不建议设置此等级,除非确认不要求数据的可靠性。
- ASYNC_WAL:异步将数据写入 HLog 日志中。
- SYNC_WAL:同步将数据写入日志文件中,需要注意的是,数据只是被写入文件系统中,并没有真正落盘。
- FSYNC_WAL:同步将数据写入日志文件并强制落盘。这是最严格的日志写入等级,可以保证数据不会丢失,但是性能相对比较差。
- USER_DEFAULT:如果用户没有指定持久化等级,默认 HBase 使用 SYNC_WAL 等级持久化数据。
WAL 写入模型
WAL 写入都需要经过三个阶段:首先将数据写入本地缓存,然后将本地缓存写入文件系统,最后执行 sync 操作同步到磁盘,可以采用“生产者-消费者”队列实现。在高并发随机写入场景下,会带来大量的 Sync 操作。HBase 中采用了 Disruptor 的 RingBuffer 来减少竞争。如果将瞬间并发写入 WAL 中的数据,合并执行 Sync 操作,可以有效降低 Sync 操作的次数,来提升写吞吐量。
对于 append,WALEdit 和 HLogKey 会被封装成 FSWALEntry 类,进而再封装成 RingBufferTruck 类放入 Disruptor 无锁有界队列中。当调用 sync 后,会生成一个 SyncFuture,再封装成 RingBufferTruck 类放入同一个队列中,然后工作线程会被阻塞,等待 notify()来唤醒。
Disruptor 框架中有且仅有一个消费者线程工作。这个框架会从 Disruptor 队列中依次取出 RingBufferTruck 对象,然后根据如下选项来操作:
- 如果 RingBufferTruck 对象中封装的是 FSWALEntry,就会执行文件 append 操作,将记录追加写入 HDFS 文件中。需要注意的是,此时数据有可能并没有实际落盘,而只是写入到文件缓存。
- 如果 RingBufferTruck 对象是 SyncFuture,会调用线程池的线程异步地批量刷盘,刷盘成功之后唤醒工作线程完成 HLog 的 sync 操作。
WAL Roll and Archive
当正在写的 WAL 文件达到一定大小以后,会创建一个新的 WAL 文件,上一个 WAL 文件依然需要被保留,因为这个 WAL 文件中所关联的 Region 中的数据,尚未被持久化存储,因此,该 WAL 可能会被用来回放数据。
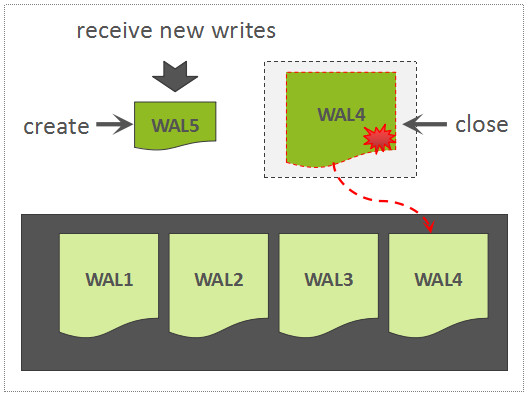
如果一个 WAL 中所关联的所有的 Region 中的数据,都已经被持久化存储了,那么,这个 WAL 文件会被暂时归档到另外一个目录中:
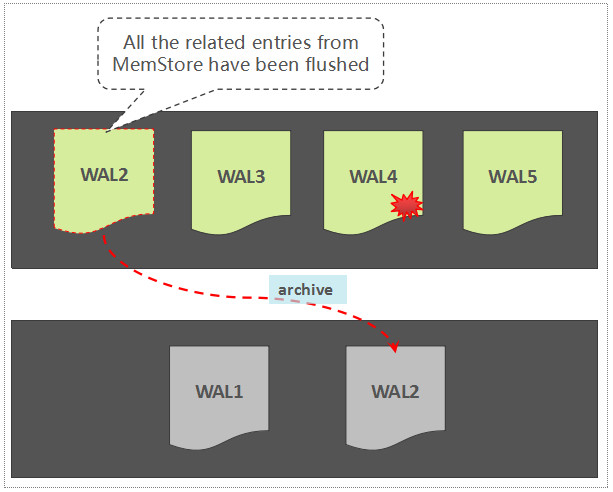
注意,这里不是直接将 WAL 文件删除掉,这是一种稳妥且合理的做法,原因如下:
- 避免因为逻辑实现上的问题导致 WAL 被误删,暂时归档到另外一个目录,为错误发现预留了一定的时间窗口
- 按时间维度组织的 WAL 数据文件还可以被用于其它用途,如增量备份,跨集群容灾等等,因此,这些 WAL 文件通常不允许直接被删除,至于何时可以被清理,还需要额外的控制逻辑
另外,如果对写入 HBase 中的数据的可靠性要求不高,那么,HBase 允许通过配置跳过写 WAL 操作。
Multi-WAL
默认情形下,一个 RegionServer 只有一个被写入的 WAL Writer,尽管 WAL Writer 依靠顺序写提升写吞吐量,在基于普通机械硬盘的配置下,此时只能有单块盘发挥作用,其它盘的 IOPS 能力并没有被充分利用起来,这是 Multi-WAL 设计的初衷。Multi-WAL 可以在一个 RegionServer 中同时启动几个 WAL Writer,可按照一定的策略,将一个 Region 与其中某一个 WAL Writer 绑定,这样可以充分发挥多块盘的性能优势。
写 MemStore
每一个 Column Family,在 Region 内部被抽象为了一个 HStore 对象,而每一个 HStore 拥有自身的 MemStore,用来缓存一批最近被随机写入的数据,这是 LSM-Tree 核心设计的一部分。
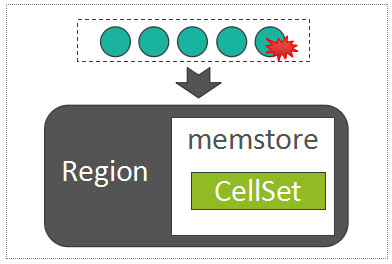
MemStore 中用来存放所有的 KeyValue 的数据结构,称之为 CellSet,而 CellSet 的核心是一个 ConcurrentSkipListMap,我们知道,ConcurrentSkipListMap 是 Java 的跳表实现,数据按照 Key 值有序存放,而且在高并发写入时,性能远高于 ConcurrentHashMap。
因此,写 MemStore 的过程,事实上是将 batch put 提交过来的所有的 KeyValue 列表,写入到 MemStore 的以 ConcurrentSkipListMap 为组成核心的 CellSet 中:
MemStore 因为涉及到大量的随机写入操作,会带来大量 Java 小对象的创建与消亡,会导致大量的内存碎片,给 GC 带来比较重的压力,HBase 为了优化这里的机制,借鉴了操作系统的内存分页的技术,增加了一个名为 MSLab 的特性,通过分配一些固定大小的 Chunk,来存储 MemStore 中的数据,这样可以有效减少内存碎片问题,降低 GC 的压力。当然,ConcurrentSkipListMap 本身也会创建大量的对象,这里也有很大的优化空间,有文章介绍过阿里如何通过优化 ConcurrentSkipListMap 的结构来有效减少 GC 时间。
Flush & Compaction
随着数据的不断写入,MemStore 中存储的数据会越来越多,系统为了将使用的内存保持在一个合理的水平,会将 MemStore 中的数据写入文件形成 HFile。Flush 阶段是 HBase 的非常核心的阶段,需要重点关注三个问题:
- MemStore Flush 的触发时机。即在哪些情况下 HBase 会触发 flush 操作。
- MemStore Flush 的整体流程。
- HFile 的构建流程。HFile 构建是 MemStore Flush 整体流程中最重要的一个部分,这部分内容会涉及 HFile 文件格式的构建、布隆过滤器的构建、HFile 索引的构建以及相关元数据的构建等。
随着 flush 产生的 HFile 文件越来越多,系统还会对 HFile 文件进行 Compaction 操作。Compaction 会从一个 Region 的一个 Store 中选择部分 HFile 文件进行合并。合并原理是,先从这些待合并的数据文件中依次读出 KeyValue,再由小到大排序后写入一个新的文件。之后,这个新生成的文件就会取代之前已合并的所有文件对外提供服务。
有关 Flush & Compaction 的内容,将会在后续文章中深入介绍。
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!