HBase 学习:读取流程
本文最后更新于:2021年6月10日 下午
和写流程相比,HBase 读数据的流程更加复杂。主要基于两个方面的原因:一是因为 HBase 一次范围查询可能会涉及多个 Region、多块缓存甚至多个数据存储文件;二是因为 HBase 中更新操作以及删除操作的实现都很简单,更新操作并没有更新原有数据,而是使用时间戳属性实现了多版本;删除操作也并没有真正删除原有数据,只是插入了一条标记为”deleted”标签的数据,而真正的数据删除发生在系统异步执行 Major Compact 的时候。很显然,这种实现思路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着套上了层层枷锁:读取过程需要根据版本进行过滤,对已经标记删除的数据也要进行过滤。本文系统地将 HBase 读取流程的各个环节串起来进行解读。
读取模式
Get
Get 是指基于确切的 RowKey 去获取一行数据,通常被称之为随机点查,这正是 HBase 所擅长的读取模式。一次 Get 操作,包含两个主要步骤:
构建 Get 对象
基于 RowKey 构建 Get 对象的最简单示例代码如下:
final byte[] key = Bytes.toBytes("66660000431^201803011300"); Get get = new Get(key);可以为构建的 Get 对象指定返回的列族:
final byte[] family = Bytes.toBytes("I"); // 指定返回列族I的所有列 get.addFamily(family);也可以直接指定返回某列族中的指定列:
final byte[] family = Bytes.toBytes("I"); final byte[] qualifierMobile = Bytes.toBytes("M"); // 指定返回列族I中的列M get.addColumn(family, qualifierMobile);发送 Get 请求并且获取对应的记录
与写数据类似,发送 Get 请求的接口也是由 Table 提供的,获取到的一行记录,被封装成一个 Result 对象。也可以这么理解一个 Result 对象:
- 关联一行数据,一定不可能包含跨行的结果
- 包含一个或多个被请求的列。有可能包含这行数据的所有列,也有可能仅包含部分列
示例代码如下:
try (Table table = conn.getTable(TABLE)) { final byte[] key = Bytes.toBytes("66660000431^201803011300"); Get get = new Get(key); // 记录Table提供的get接口获取一行记录 Result result = table.get(get); // 通过CellScanner来遍历该Result中的所有列 CellScanner scanner = result.cellScanner(); while (scanner.advance()) { Cell cell = scanner.current(); // 读取Cell中的信息... } }上面给出的是一次随机获取一行记录的例子,但事实上,一次获取多行记录的需求也是普遍存在的,Table 中也定义了 Batch Get 的接口,这样可以在一次网络请求中同时获取多行数据。示例代码如下:
try (Table table = conn.getTable(TN)) { // 基于多个Get对象构建一个List List<Get> gets = new ArrayList<>(8); gets.add(new Get(Bytes.toBytes("11110000431^201803011300"))); gets.add(new Get(Bytes.toBytes("22220000431^201803011300"))); gets.add(new Get(Bytes.toBytes("33330000431^201803011300"))); gets.add(new Get(Bytes.toBytes("44440000431^201803011300"))); gets.add(new Get(Bytes.toBytes("55550000431^201803011300"))); gets.add(new Get(Bytes.toBytes("66660000431^201803011300"))); gets.add(new Get(Bytes.toBytes("77770000431^201803011300"))); gets.add(new Get(Bytes.toBytes("88880000431^201803011300"))); // 调用Table的Batch Get的接口获取多行记录 Result[] results = table.get(gets); for (Result result : results) { CellScanner scanner = result.cellScanner(); while (scanner.advance()) { Cell cell = scanner.current(); // 读取Cell中的信息... } } }关于 Batch Get 需要补充说明一点信息:获取到的 Result 列表中的结果的顺序,与给定的 RowKey 顺序是一致的。
Scan
HBase 中的数据表通过划分成一个个的 Region 来实现数据的分片,每一个 Region 关联一个 RowKey 的范围区间,而每一个 Region 中的数据,按 RowKey 的字典顺序进行组织。
正是基于这种设计,使得 HBase 能够轻松应对这类查询:”指定一个 RowKey 的范围区间,获取该区间的所有记录”, 这类查询在 HBase 被称之为 Scan。
从技术实现的角度来看,get 请求也是一种 scan 请求(最简单的 scan 请求,scan 的条数为 1)。从这个角度讲,所有读取操作都可以认为是一次 scan 操作。
HBase Client 端与 Server 端的 scan 操作并没有设计为一次 RPC 请求,这是因为一次大规模的 scan 操作很有可能就是一次全表扫描,扫描结果非常之大,通过一次 RPC 将大量扫描结果返回客户端会带来至少两个非常严重的后果:
- 大量数据传输会导致集群网络带宽等系统资源短时间被大量占用,严重影响集群中其他业务。
- 客户端很可能因为内存无法缓存这些数据而导致客户端 OOM。
实际上 HBase 会根据设置条件将一次大的 scan 操作拆分为多个 RPC 请求,每个 RPC 请求称为一次 next 请求,每次只返回规定数量的结果。
一次 Scan 操作,包括如下几个关键步骤:
构建 Scan
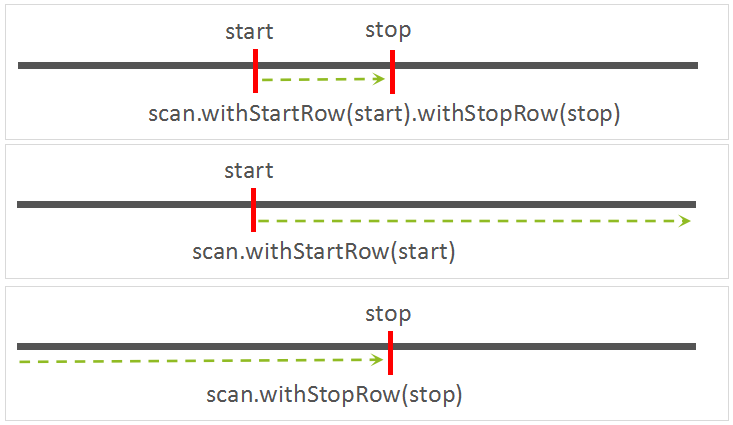
最简单也最常用的构建 Scan 对象的方法,就是仅仅指定 Scan 的 StartRow 与 StopRow。示例如下:
final byte[] startKey = Bytes.toBytes("66660000431^20180301"); final byte[] stopKey = Bytes.toBytes("66660000431^20180501"); Scan scan = new Scan(); /** * 2.0版本之前,设置Scan Key Range的接口为: * scan.setStartRow(startKey).setStopRow(stopKey); * 但在2.0版本中,该接口已经被标注为Deprecated接口,即已不推荐使用. * 下面是推荐的接口: */ scan.withStartRow(startKey).withStopRow(stopKey);如果 StartRow 未指定,则本次 Scan 将从表的第一行数据开始读取。
如果 StopRow 未指定,而且在不主动停止本次 Scan 操作的前提下,本次 Scan 将会一直读取到表的最后一行记录。
如果 StartRow 与 StopRow 都未指定,那本次 Scan 就是一次全表扫描操作。
同 Get 类似,Scan 也可以主动指定返回的列族或列:
final byte[] family = Bytes.toBytes("I"); /** * 为本次Scan操作指定返回的列族 * scan.addFamily(family); */ final byte[] qualifierMobile = Bytes.toBytes("M"); scan.addColumn(family, qualifierMobile);获取 ResultScanner
ResultScanner scanner = table.getScanner(scan);遍历查询结果
Result result = null; // 通过scanner.next方法获取返回的每一行数据 while ((result = scanner.next()) != null) { // 读取result中的结果... }每执行一次 next()操作,客户端先会从本地缓存中检查是否有数据,如果有就直接返回给用户,如果没有就发起一次 RPC 请求到服务器端获取,获取成功之后缓存到本地。
关闭 ResultScanner
通过下面的方法可以关闭一个 ResultScanner:
scanner.close();如果基于 Java 传统的 try-catch-finally 语法,上述 close 方式需要在 finally 模块显式调用。但如果是是基于 try-with-resource 语法,则由 Java 框架自动调用。
将上面 1~4 步骤联合起来的示例代码如下:
try (Table table = conn.getTable(TABLE)) { final byte[] start = Bytes.toBytes("66660000431^20180301"); final byte[] stop = Bytes.toBytes("66660000431^20180501"); Scan scan = new Scan(); scan.withStartRow(start).withStopRow(stop); // 基于try-with-resource语法,try语句块结束后 // scanner的close方法会自动被调用 try (ResultScanner scanner = table.getScanner(scan)) { Result result = null; while ((result = scanner.next()) != null) { // 读取result中的结果... } } }
Scan 参数设置
Caching: 设置一次 RPC 请求批量读取的 Results 数量
下面的示例代码设定了一次读取回来的 Results 数量为 100:
scan.setCaching(100);Client 每一次往 RegionServer 发送 scan 请求,都会批量拿回一批数据(由 Caching 决定过了每一次拿回的 Results 数量),然后放到本次的 Result Cache 中:
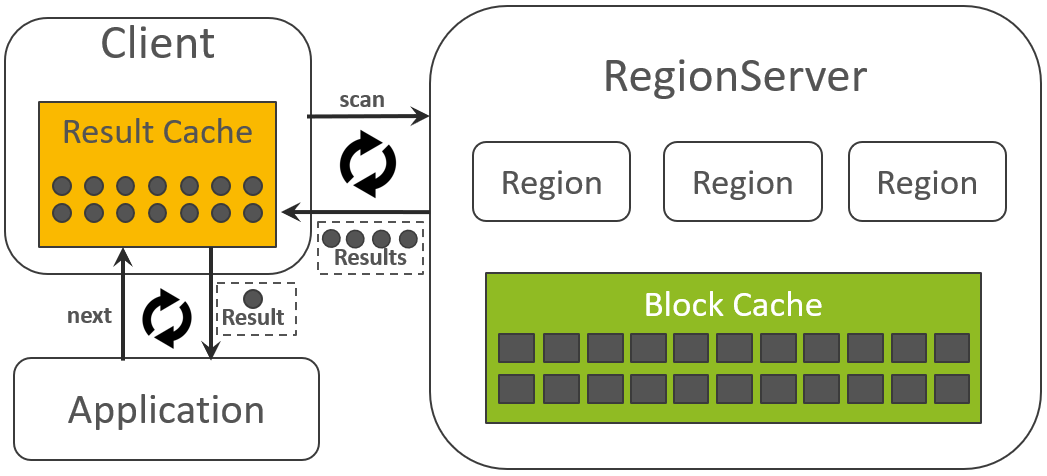
应用每一次读取数据时,都是从本地的 Result Cache 中获取的。如果 Result Cache 中的数据读完了,则 Client 会再次往 RegionServer 发送 scan 请求获取更多的数据。
Batch: 设置每一个 Result 中的列的数量
下面的示例代码设定了每一个 Result 中的列的数量的限制值为 3:
scan.setBatch(3);该参数适用于一行数据过大的场景,这样,一行数据被请求的列会被拆成多个 Results 返回给 Client。
Limit: 限制一次 Scan 操作所获取的行的数量
同 SQL 语法中的 limit 子句,限制一次 Scan 操作所获取的行的总量:
scan.setLimit(10000);CacheBlock: RegionServer 侧是否要缓存本次 Scan 所涉及的 HFileBlocks
scan.setCacheBlocks(true);Raw Scan: 是否可以读取到删除标识以及被删除但尚未被清理的数据
scan.setRaw(true);MaxResultSize: 从内存占用量的维度限制一次 Scan 的返回结果集
下面的示例代码将返回结果集的最大值设置为 5MB:
scan.setMaxResultSize(5 * 1024 * 1024);Reversed Scan: 反向扫描
普通的 Scan 操作是按照字典顺序从小到大的顺序读取的,而 Reversed Scan 则恰好相反:
scan.setReversed(true);带 Filter 的 Scan
Filter 可以在 Scan 的结果集基础之上,对返回的记录设置更多条件值,这些条件可以与 RowKey 有关,可以与列名有关,也可以与列值有关,还可以将多个 Filter 条件组合在一起,等等。
最常用的 Filter 是 SingleColumnValueFilter,基于它,可以实现如下类似的查询:”返回满足条件{列I:D的值大于等于 10}的所有行”
示例代码如下:
Filter filter = new SingleColumnValueFilter(FAMILY, QUALIFIER, CompareOperator.GREATER_OR_EQUAL, Bytes.toBytes("10")); scan.setFilter(filter);Filter 丰富了 HBase 的查询能力,但使用 Filter 之前,需要注意一点:Filter 可能会导致查询响应时延变的不可控制。因为我们无法预测,为了找到一条符合条件的记录,背后需要扫描多少数据量,如果在有效限制了 Scan 范围区间(通过设置 StartRow 与 StopRow 限制)的前提下,该问题能够得到有效的控制。这些信息都要求使用 Filter 之前应该详细调研自己的业务数据模型。
客户端发送请求
无论是 Get,还是 Scan,Client 在发送请求到 RegionServer 之前,也需要先获取路由信息:
定位该请求所关联的 Region:
因为 Get 请求仅关联一个 RowKey,所以,直接定位该 RowKey 所关联的 Region 即可。
对于 Scan 请求,先定位 Scan 的 StartRow 所关联的 Region。
往该 Region 所关联的 RegionServer 发送读取请求:
与写入流程中的数据路由过程类似。如果一次 Scan 涉及到跨 Region 的读取,读完一个 Region 的数据以后,需要继续读取下一个 Region 的数据,这需要在 Client 侧不断记录和刷新 Scan 的进展信息。如果一个 Region 中已无更多的数据,在 scan 请求的响应结果中会带有提示信息,这样可以让 Client 侧切换到下一个 Region 继续读取。
服务端处理请求
从宏观视角来看,一次 scan 可能会同时扫描一张表的多个 Region,对于这种扫描,客户端会根据 hbase:meta 元数据将扫描的起始区间[startKey,stopKey)进行切分,切分成多个互相独立的查询子区间,每个子区间对应一个 Region。RegionServer 接收到客户端的 get/scan 请求之后做了两件事情:首先构建 scanner iterator 体系;然后执行 next 函数获取 KeyValue,并对其进行条件过滤。
Scanner Iterator 体系
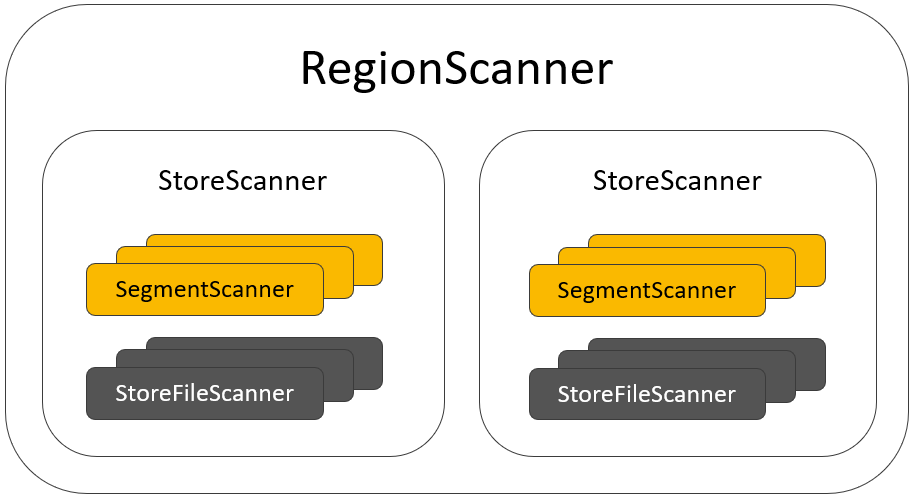
在 Store/Column Family 内部,KeyValue 可能存在于 MemStore 的 Segment 中,也可能存在于 HFile 文件中,无论是 Segment 还是 HFile,我们统称为 KeyValue 数据源。HBase 使用了各种 Scanner 来抽象每一层/每一类 KeyValue 数据源的 Scan 操作:
- 关于一个 Region 的读取,被封装成一个 RegionScanner 对象。
- 每一个 Store/Column Family 的读取操作,被封装在一个 StoreScanner 对象中。
- SegmentScanner 与 StoreFileScanner 分别用来描述关于 MemStore 中的 Segment 以及 HFile 的读取操作。
- StoreFileScanner 中关于 HFile 的实际读取操作,由 HFileScanner 完成。
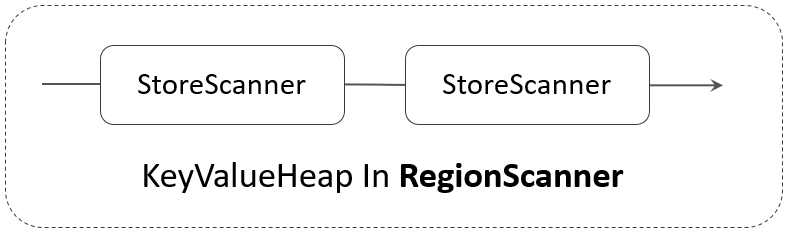
RegionScanner 的构成如下图所示:
在 StoreScanner 内部,多个 SegmentScanner 与多个 StoreFileScanner 被组织在一个称之为 KeyValueHeap 的对象中:
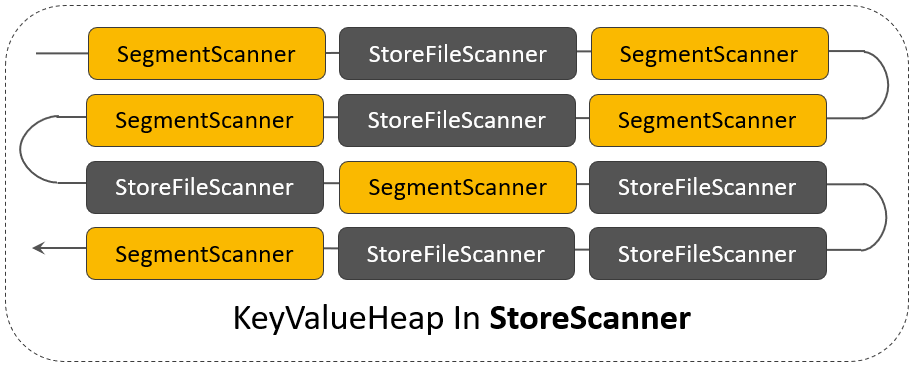
每一个 Scanner 内部有一个指针指向当前要读取的 KeyValue,KeyValueHeap 的核心是一个优先级队列(PriorityQueue),在这个 PriorityQueue 中,按照每一个 Scanner 当前指针所指向的 KeyValue 进行排序:
// 用来组织所有的Scanner
protected PriorityQueue<KeyValueScanner> heap = null;
// PriorityQueue当前排在最前面的Scanner
protected KeyValueScanner current = null;同样的,RegionScanner 中的多个 StoreScanner,也被组织在一个 KeyValueHeap 对象中:
KeyValueScanner
KeyValueScanner 定义了读取 KeyValue 的基础接口:
/**
* 查看当前Scanner中当前指针位置的KeyValue,该接口不会移动指针.
*/
Cell peek();
/**
* 返回Scanner当前指针位置的KeyValue,而后移动指针到下一个KeyValue.
*/
Cell next() throws IOException;
/**
* 将当前Scanner的指针定位到指定的KeyValue的位置,如果不存在,则定位到
* 比该Cell大的下一个KeyValue位置.Seek操作会从当前的HFile Block的开
* 始位置查找.
*/
boolean seek(Cell key) throws IOException;
/**
* 与seek接口类似,也是将当前Scanner的指针定位到指定的KeyValue的位置,
* 如果不存在,则定位到比该KeyValue大的下一个KeyValue位置.与seek接口不
* 同点在于,该操作会从上一次读到的HFile Block的位置开始查找.
*/
boolean reseek(Cell key) throws IOException;
/**
* 与seek/reseek类似,但不同点在于采用了Lazy Seek机制来降低磁盘IO请求,
* 其原理在于充分利用Bloom Filter的判断结果,以及待Seek的KeyValue与该
* Scanner中最大时间戳的对比,减少一些不必要的Seek操作
*/
boolean requestSeek(Cell kv, boolean forward,
boolean useBloom) throws IOException;实现了 KeyValueScanner 接口类的主要 Scanner 包括:
- StoreFileScanner
- SegmentScanner
- StoreScanner
RegionScanner 初始化
RegionScanner 初始化过程,包括几个关键操作:
获取 ReadPoint
ReadPoint 决定了此次 Scan 操作能看到哪些数据。Scan 过程中新写入的数据,对此次 Scan 是不可见的。
按需选择对应的 Store,并初始化对应的 StoreScanner
StoreScanner 在初始化的时候,也会按需选择对应的 SegmentScanner 以及 StoreFileScanner,筛选规则包括:
- 如果一次 Scan 操作指定了 Time Range,则只选择与该 Time Range 有关的 Scanners。
- 对于 Get 操作,可以通过 BloomFilter 过滤掉不符合条件的 Scanners。
StoreScanner 中筛选除了 Scanner 以后,会将每一个 Scanner seek 到 Scan 的 StartRow 位置:
RegionScanner 读取流程
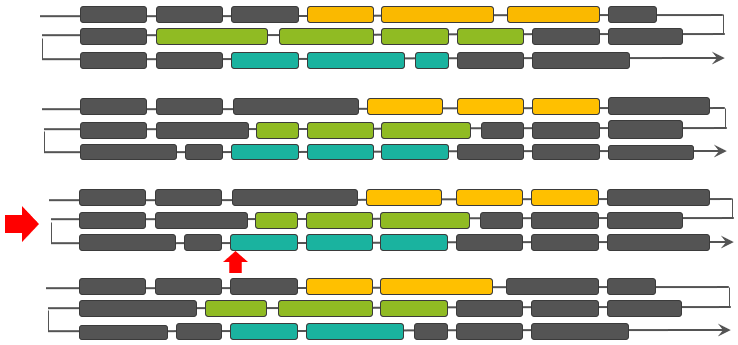
为了简单的解释该流程,我们先假定一个 RegionScanner 中仅包含一个 StoreScanner,那么,这个 RegionScanner 中的核心读取操作,是由 StoreScanner 完成的,我们进一步假定 StoreScanner 由 4 个 Scanners 组成(我们泛化了 SegmentScanner 与 StoreFileScanner 的区别,统称为 Scanner),直观起见,在下图中我们使用了四种不同的颜色:

每一个 Scanner 中都有一个 current 指针指向下一个即将要读取的 KeyValue,KeyValueHeap 中的 PriorityQueue 正是按照每一个 Scanner 的 current 所指向的 KeyValue 进行排序。
第一次 next 请求,将会返回 ScannerA 中的 Row01:FamA:Col1,而后 ScannerA 的指针移动到下一个 KeyValue Row01:FamA:Col2,PriorityQueue 中的 Scanners 排序依然不变:

第二次 next 请求,依然返回 ScannerA 中的 Row01:FamA:Col2,ScannerA 的指针移动到下一个 KeyValue Row02:FamA:Col1,此时,PriorityQueue 中的 Scanners 排序发生了变化:

下一次 next 请求,将会返回 ScannerB 中的 KeyValue,周而复始,直到某一个 Scanner 所读取的数据耗尽,该 Scanner 将会被 close,不再出现在上面的 PriorityQueue 中。
SegmentScanner/StoreFileScanner 中返回的 KeyValue,包含了各种类型的 KeyValue:
- 已被更新过的旧 KeyValue
- 已被标记删除但尚未被及时清理的 KeyValue
- 已过期的尚未被及时清理的 KeyValue
- 用来描述一次删除操作的 KeyValue(删除还包含了多种类型)
- 承载最新用户数据的普通 KeyValue
因此,在 StoreScanner 层,需要对这些 KeyValue 做更复杂的逻辑校验,这些校验由 ScanQueryMatcher 完成。默认地,可作为返回数据的 KeyValue,应该满足如下条件:
- KeyValue 类型为 Put
- KeyValue 所关联的列为用户 Scan 所涉及的列
- KeyValue 的时间戳符合 Scan 的 TimeRange 要求
- 版本最新
- 未被标记删除
- 通过了 Filter 的过滤条件
上述条件,只针对一些普通的 Scan,不同的 Scan 参数配置,可能会导致条件集发生变化,如 Scan 启用了 Raw Scan 模式时,Delete 类型的 KeyValue 也会被返回。
在 Scanner 中,如果允许读取多个版本(由 Scan#readVersions 配置),那正常的读取顺序应该为:
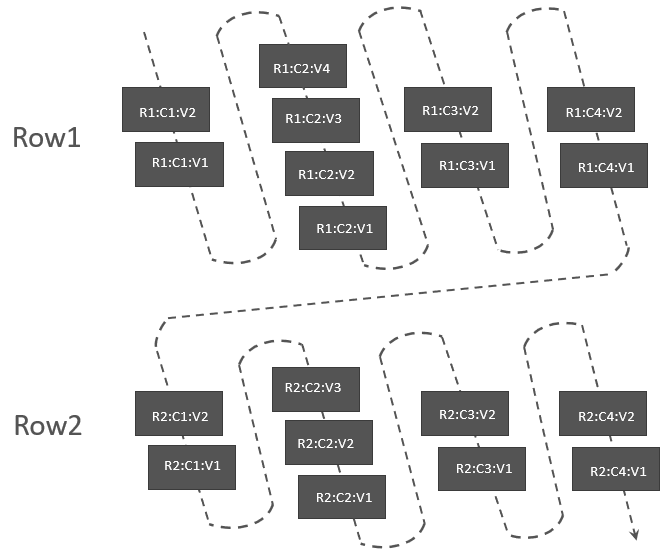
上面这种读取的顺序与实际存在的数据的逻辑顺序也是相同的。
由于不同的 Scan 所读取的每一行中的数据不同,有的限定了列的数量,有的限定了版本的数量,这使得读取时可以通过一些优化,减少不必要的数据扫描。如某次 Scan 在允许读多个版本的同时,限定了只读取 C1~C3,那么,读取顺序应该为:
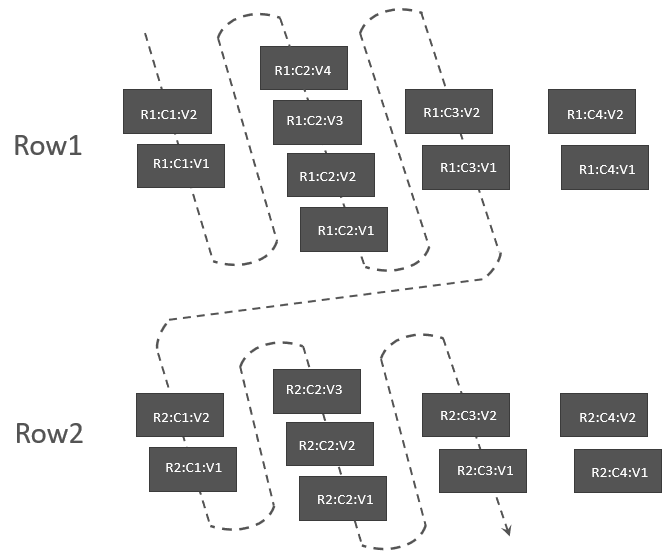
最普通的 Scan,其实只需要读取每一列的最新版本即可,那读取的顺序应该为:
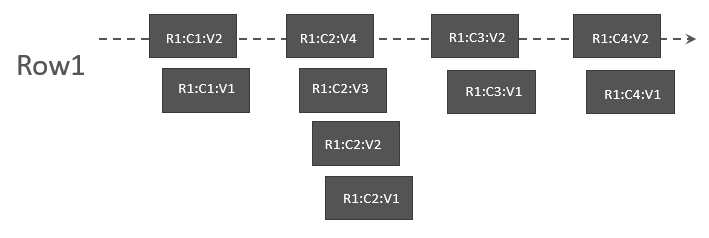
我们知道 KeyValueScanner 定义了基础的 seek/reseek/requestSeek 等接口,可以将指针移动到指定 KeyValue 位置。关于指针如何移动的决策信息,由 ScanQueryMatcher 提供的。ScanQueryMatcher 对每一个 KeyValue 的逻辑检查结果称之为 MatchCode,MatchCode 不仅包含了是否应该返回该 KeyValue 的结果,还可能给出了 Scanner 的下一步操作的提示信息。关于它的枚举值,简单举例如下:
INCLUDE_AND_SEEK_NEXT_ROW
包含当前 KeyValue,并提示 Scanner 当前行已无需继续读取,请 Seek 到下一行。
INCLUDE_AND_SEEK_NEXT_COL
包含当前 KeyValue,并提示 Scanner 当前列已无需继续读取,请 Seek 到下一列。
无论是 StoreScanner 还是 RegionScanner,返回的都是符合条件的 KeyValue 列表。这些 KeyValues 在 RSRpcServices 层被进一步组装成 Results 响应给 Client 侧。
从HFile中读取待查找Key
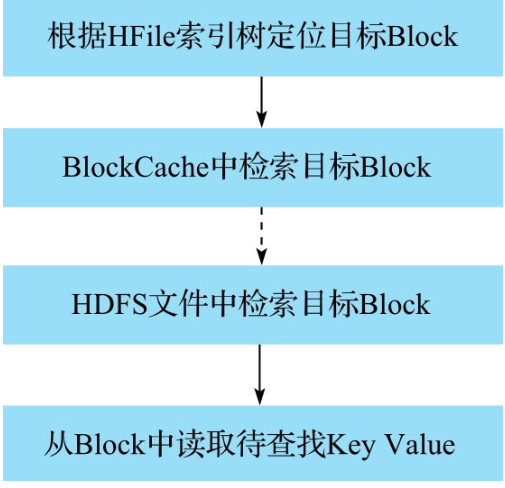
在一个 HFile 文件中 seek 待查找的 Key,该过程可以分解为 4 步操作:
根据 HFile 索引树定位目标 Block
HRegionServer 打开 HFile 时会将所有 HFile 的 Trailer 部分和 Load-on-open 部分加载到内存,Load-on-open 部分有个非常重要的 Block——Root Index Block,即索引树的根节点。在 Root Index Block 中通过二分查找定位中间节点。因为 Root Index Block 常驻内存,所以这个过程很快。将中间节点索引块加载到内存,然后通过二分查找定位叶子节点。最终访问最后需要访问索引指向的 Data Block 节点。
上述流程中,Intermediate Index Block、Leaf Index Block 以及 Data Block 都需要加载到内存,所以一次查询的 IO 正常为 3 次。但是实际上 HBase 为 Block 提供了缓存机制,可以将频繁使用的 Block 缓存在内存中,以便进一步加快实际读取过程。
BlockCache 中检索目标 Block
Block 缓存到 BlockCache 之后会构建一个 Map,Map 的 Key 是 BlockKey,Value 是 Block 在内存中的地址。其中 BlockKey 由两部分构成——HFile 名称以及 Block 在 HFile 中的偏移量。BlockKey 很显然是全局唯一的。根据 BlockKey 可以获取该 Block 在 BlockCache 中内存位置,然后直接加载出该 Block 对象。如果在 BlockCache 中没有找到待查 Block,就需要在 HDFS 文件中查找。
HDFS 文件中检索目标 Block
根据文件索引提供的 Block Offset 以及 Block DataSize 这两个元素可以在 HDFS 上读取到对应的 Data Block 内容(核心代码可以参见 HFileBlock.java 中内部类 FSReaderImpl 的 readBlockData 方法)。这个阶段 HBase 会下发命令给 HDFS,HDFS 执行真正的 Data Block 查找工作。
从 Block 中读取待查找 KeyValue
HFile Block 由 KeyValue(由小到大依次存储)构成,但这些 KeyValue 并不是固定长度的,只能遍历扫描查找。
如图所示:
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!